

1. Descripción
El siguiente documento se detalla la integración de las herramientas Attunity Replicate y Apache kafka utilizando Amazon Managed Streaming for Apache Kafka (Amazon MSK), Con el objetivo de realizar ingesta de datos en tiempo real y ser consumidos desde múltiples plataformas. Se presentará la instalación de las herramientas, configuración y posterior integración, mediante un caso de uso de ejemplo.
2. Conceptos
2.1. Apache Kafka
2.1.1. ¿Qué es Apache Kafka?
- Apache Kafka es una plataforma de transmisión distribuida de datos en tiempo real.
- Permite almacenar flujos de registros de una manera duradera y tolerante a fallas.
- Procesa flujos de registros a medida que ocurren.
- Alto rendimiento: diseñado para una gran cantidad de mensajes pequeños
- Se utiliza para construir pipelines de datos de transmisión en tiempo real y aplicaciones de transmisión.
2.1.2. Terminología
| Broker | Servidor Kafka. Varios broker forman un cluster. |
| Cluster | Grupo de dos o más brokers que brindan redundancia y escalabilidad |
| Producer | Cliente Kafka. Es quien envía los mensajes al broker. |
| Consumer | Cliente Kafka. Es quien recibe los mensajes desde el broker. |
| Topic | Un topic es una categoría en la que se publican los registros. Cada Topic de Kafka puede tener desde cero a muchos consumidores que se suscriben a los datos escritos en él. |
| Partition | Subconjunto de topics creado para permitir la redundancia y lectura / escritura paralela para un mayor rendimiento |
| Message | Cualquier búfer (texto / binario). El formato debe coordinarse entre producers y consumers |
| Message Key | Opcional. Utilizado para particionamiento y compactación. |
| Offset | Posición de un mensaje en una partición. Utilizado por el consumidor. |
2.2. Amazon MSK
2.2.1. ¿Qué es Amazon MSK?
- Amazon MSK es un servicio completamente administrado que facilita la tarea de crear y ejecutar aplicaciones que utilizan Apache Kafka para procesar datos de streaming.
- Con unos clics en la consola de Amazon MSK, puede crear clústeres de Apache Kafka de alta disponibilidad con ajustes y configuraciones basados en las prácticas recomendadas de implementación de Apache Kafka.
2.3. Attunity Replicate
2.3.1. ¿Qué es Attunity Replicate?
- Es una herramienta que permite a las empresas acelerar la replicación, ingesta y transmisión de datos en una gran variedad de bases de datos, data warehouses y plataformas de Big Data.
- Facilita el mover grandes volúmenes de datos con seguridad, eficacia, y con un impacto muy bajo en las operaciones.
- Simplifica la ingesta masiva en plataformas de Big Data desde miles de fuentes.

3. Cluster Amazon MSK
Antes de crear un clúster de Amazon MSK se deben realizar configuraciones preliminares para desplegar su entorno.
3.1. Crear una VPC para el clúster de MSK
En el primer paso de la Introducción al uso de Amazon MSK, se utiliza la Consola de Amazon VPC para crear una Amazon Virtual Private Cloud (Amazon VPC). Creará un Clúster de MSK en esta VPC más adelante.
Para realizar esta acción debe seguir los siguientes pasos:
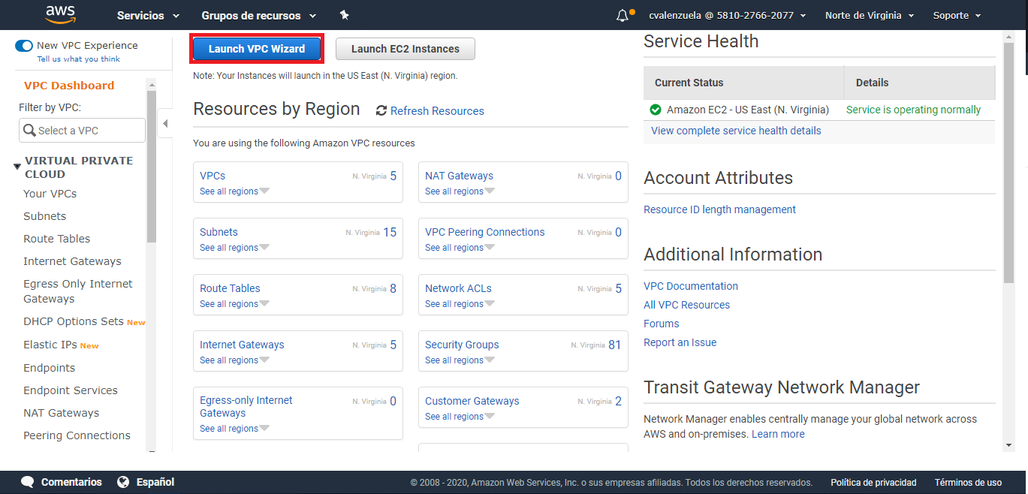
- Paso 1: Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon VPC en https://console.aws.amazon.com/vpc/
- Paso 2: Elija Launch VPC Wizard (Lanzar el asistente de VPC).
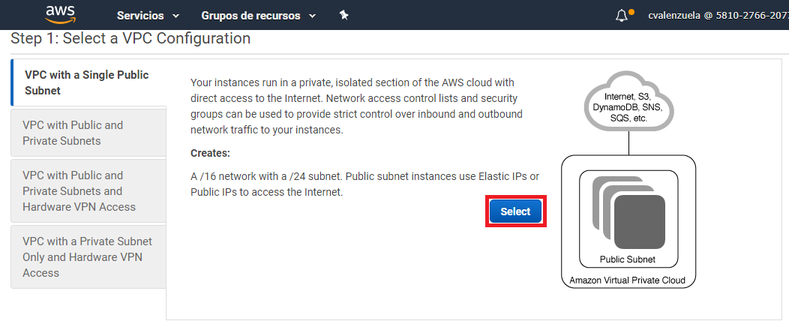
Paso 3: Seleccione Select (Seleccionar) para aceptar la configuración predeterminada de Amazon VPC, denominada VPC with a Single Public Subnet (VPC con una única subred pública).
- Paso 4: En VPC name (Nombre de VPC), escriba el nombre de su VPC.
Ejemplo: AWS-MSK-VPC
- Paso 5: En Availability Zone (Zona de disponibilidad), elija us-east-1a.
- Paso 6: En Subnet name (Nombre de subred), escriba nombre de la subred.
Ejemplo: AWS-MSK-VPCSubnet-1
- Paso 7: Elija Create VPC (Crear VPC) y, a continuación, elija OK (Aceptar).
3.2. Añadir subredes a la VPC
Para asegurar la alta disponibilidad y la tolerancia a errores Amazon MSK requiere que sea distribuido en más de una subred y en más de una zona de disponibilidad.
Amazon MSK requiere que se creen mínimo 2 y máximo 3 subredes cada una en una zona de disponibilidad distinta.
Para realizar esta acción debe seguir los siguientes pasos:
- Paso 1: Abra la consola de Amazon VPC en https://console.aws.amazon.com/vpc/.
- Paso 2: En el panel de navegación, elija Subnets.
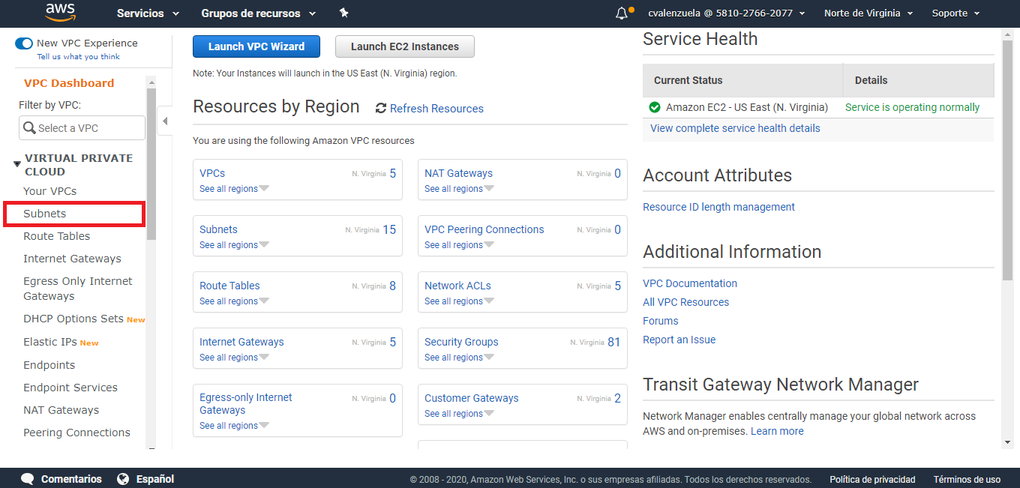
- Paso 3: En la lista de subredes, busque la subred creada anteriormente y, a continuación, busque la columna denominada Route table (Tabla de enrutamiento). Copie el valor asociado a la subred en dicha columna y guárdelo para más adelante.
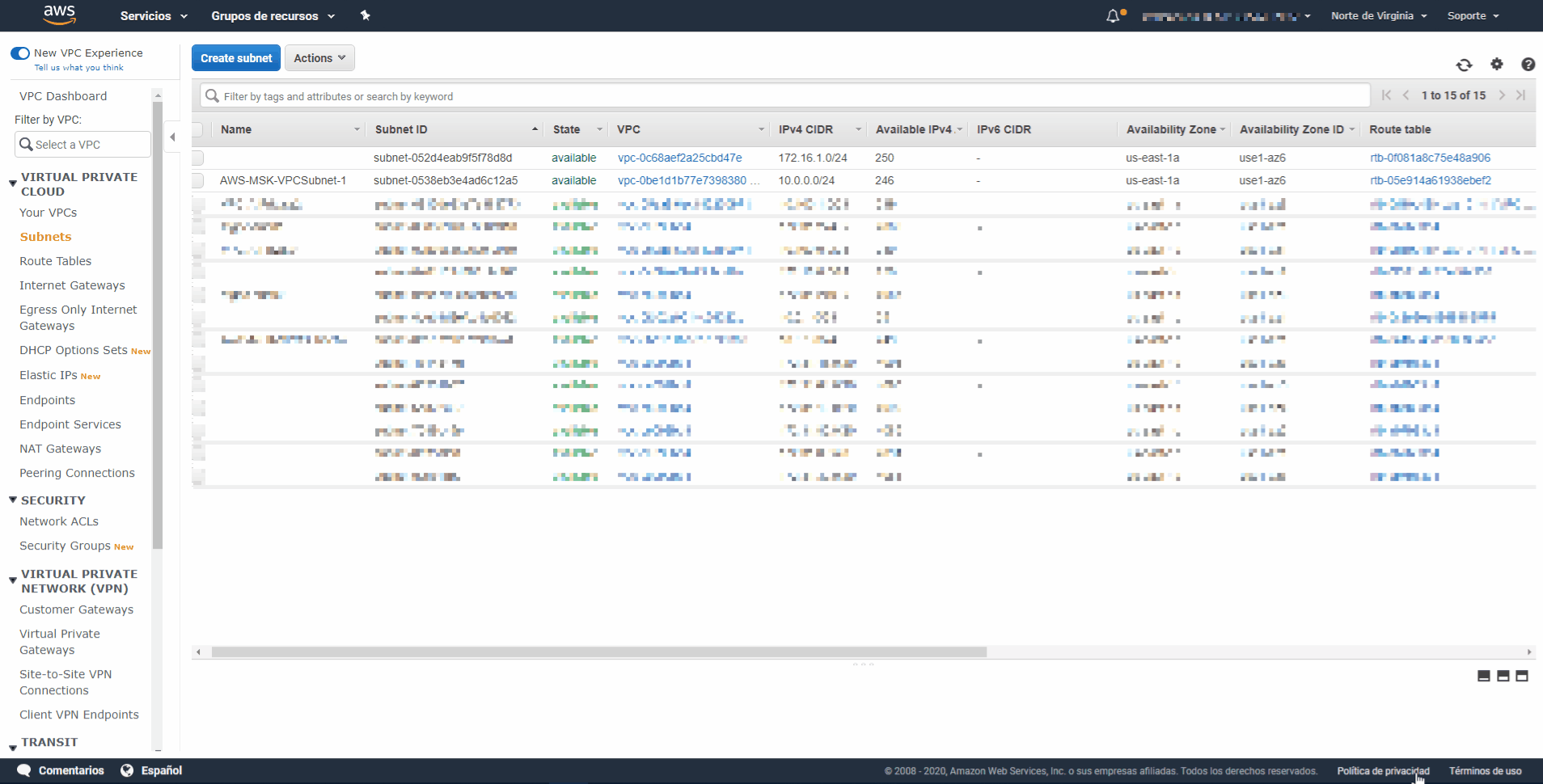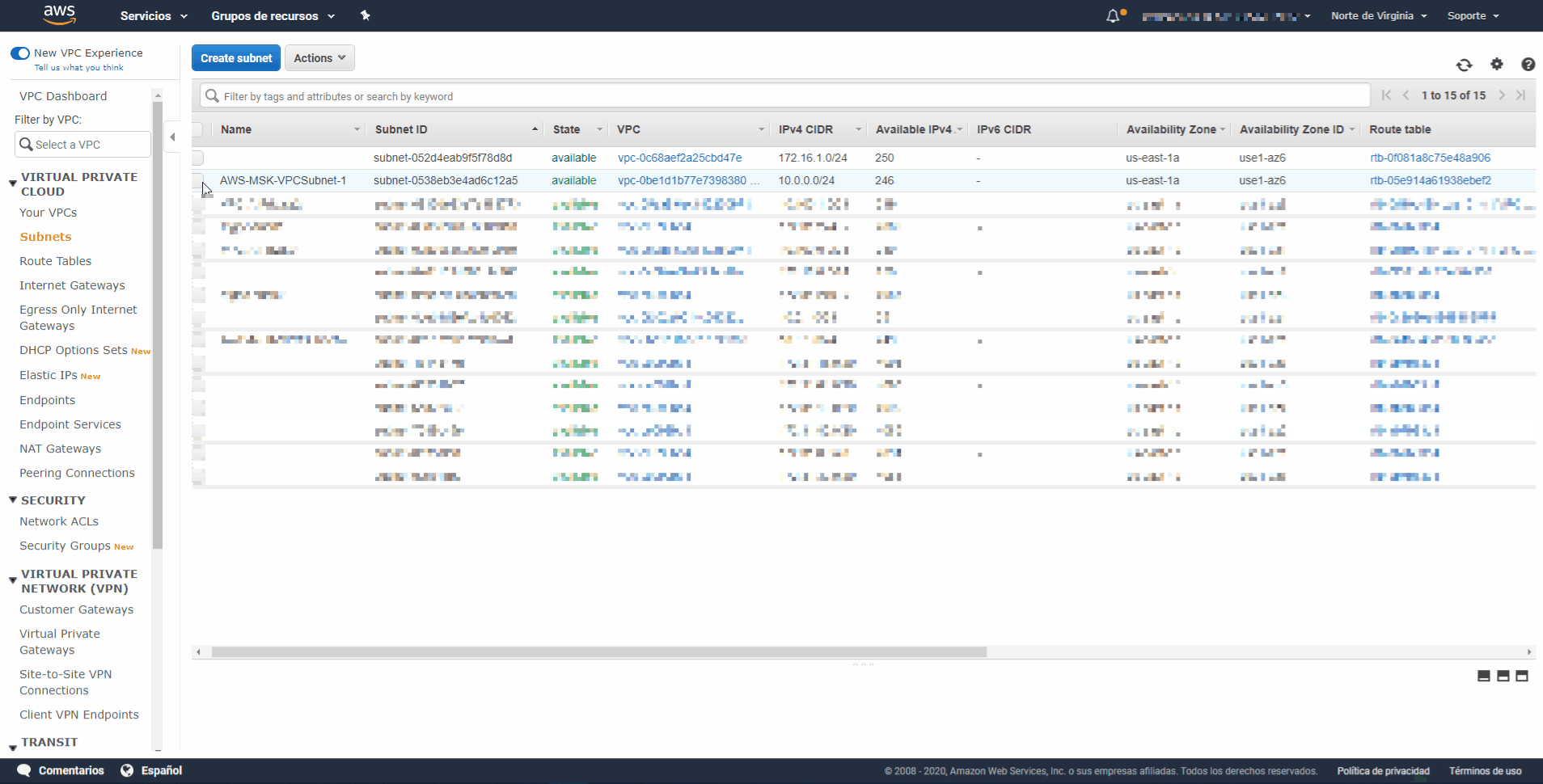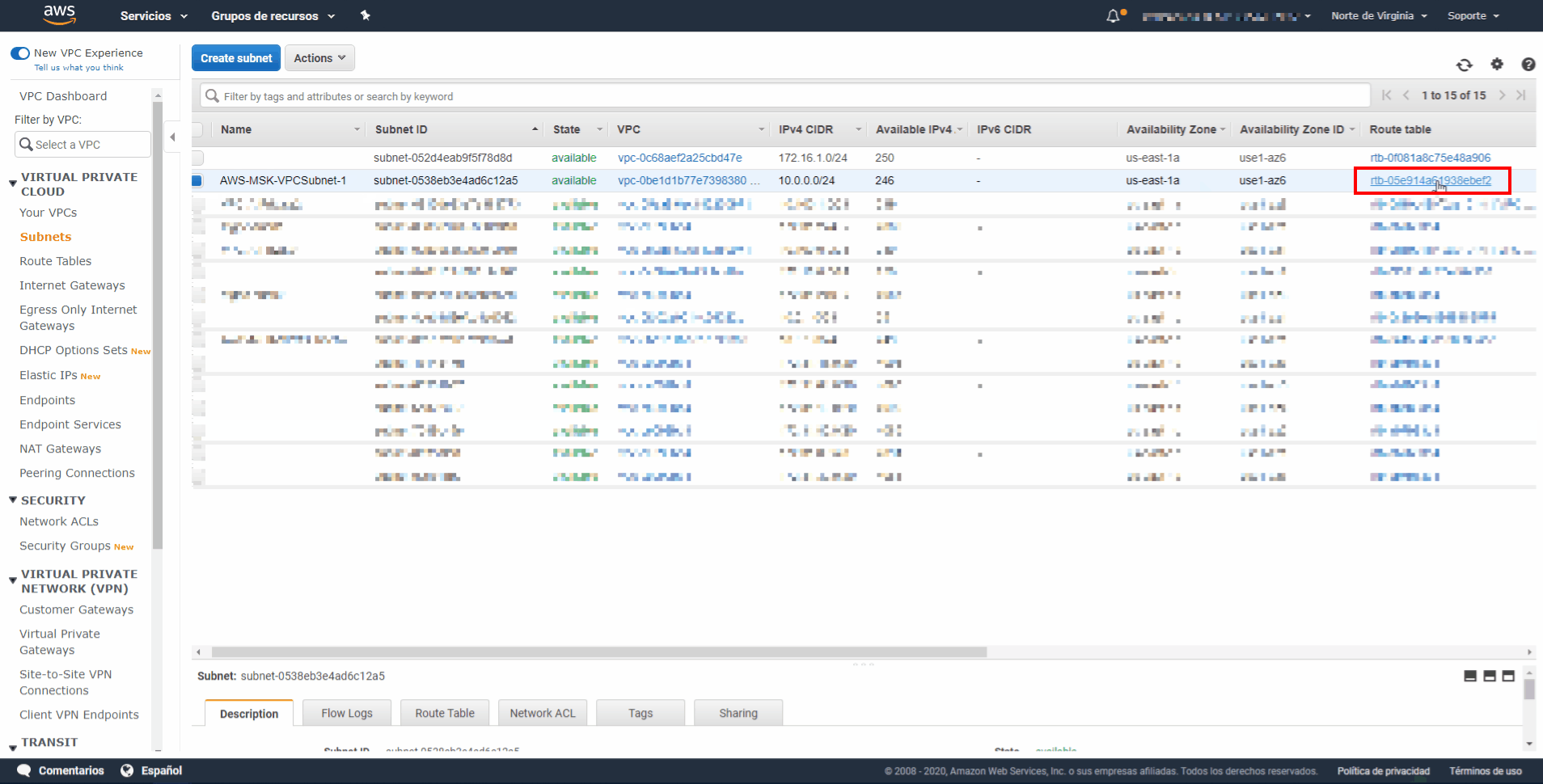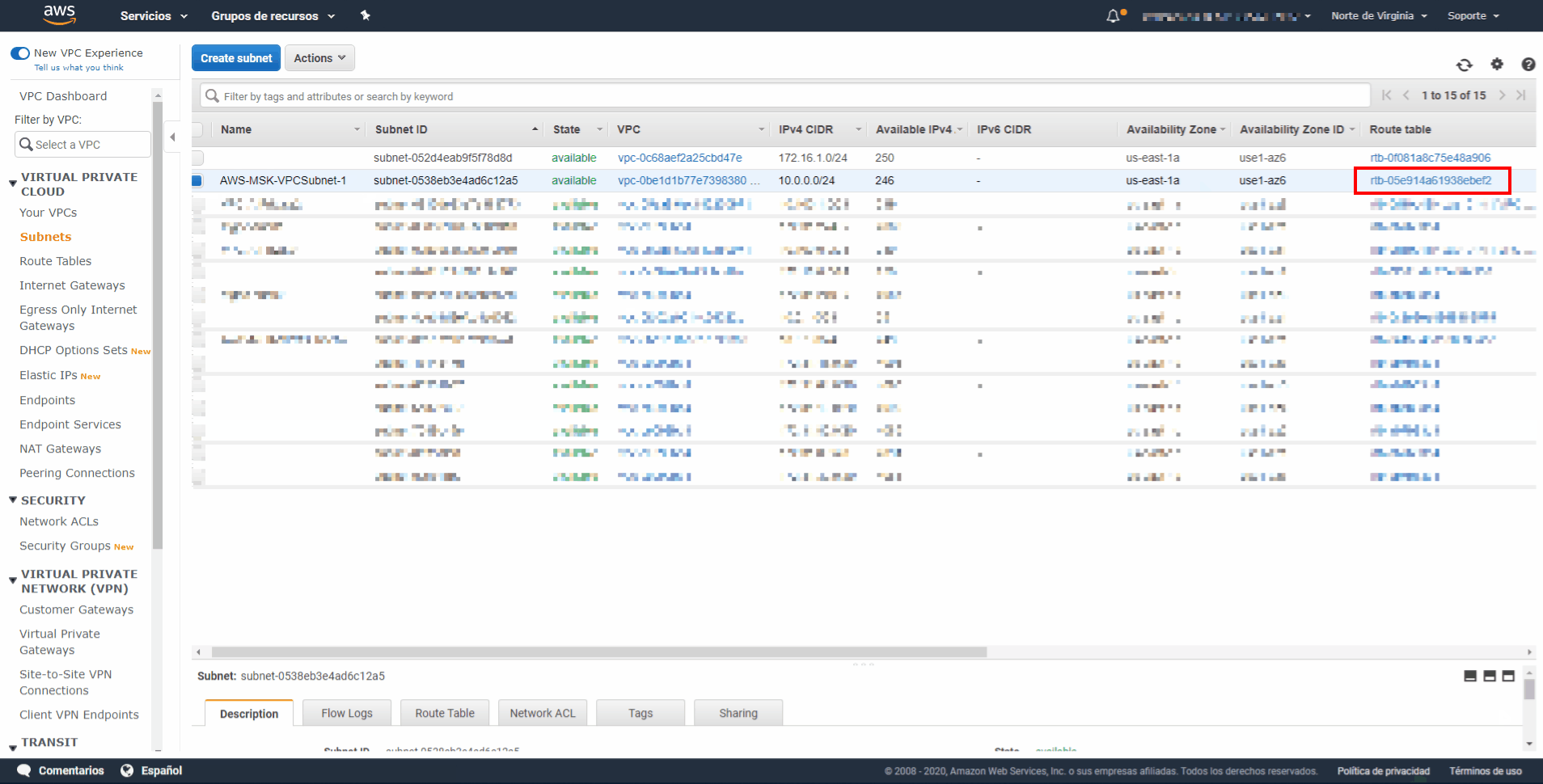
- Paso 4: Elija Create subnet (Crear subred).
- Paso 5: En la etiqueta Name (Nombre), escriba el nombre de la subred.
Ejemplo: AWS-MSK-VPCSubnet-2
- Paso 6: En VPC, elija la VPC creada en el punto anterior.
- Paso 7: En Availability Zone (Zona de disponibilidad), elija us-east-1b.
- Paso 8: En IPv4 CIDR block (Bloque de CIDR IPv4), escriba 10.0.1.0/24.
- Paso 9: Elija Create (Crear) y, a continuación, Close (Cerrar).
- Paso 10: Elija la sub
red recién creada en la lista de subredes seleccionando la casilla de verificación situada junto a ella. Asegúrese de que no hay ninguna otra casilla de verificación seleccionada en la lista. - Paso 11: En la vista de subred situada cerca de la parte inferior de la página, elija la pestaña Route Table (Tabla de enrutamiento) y, a continuación, elija Edit route table association (Editar asociación de tabla de enrutamiento).
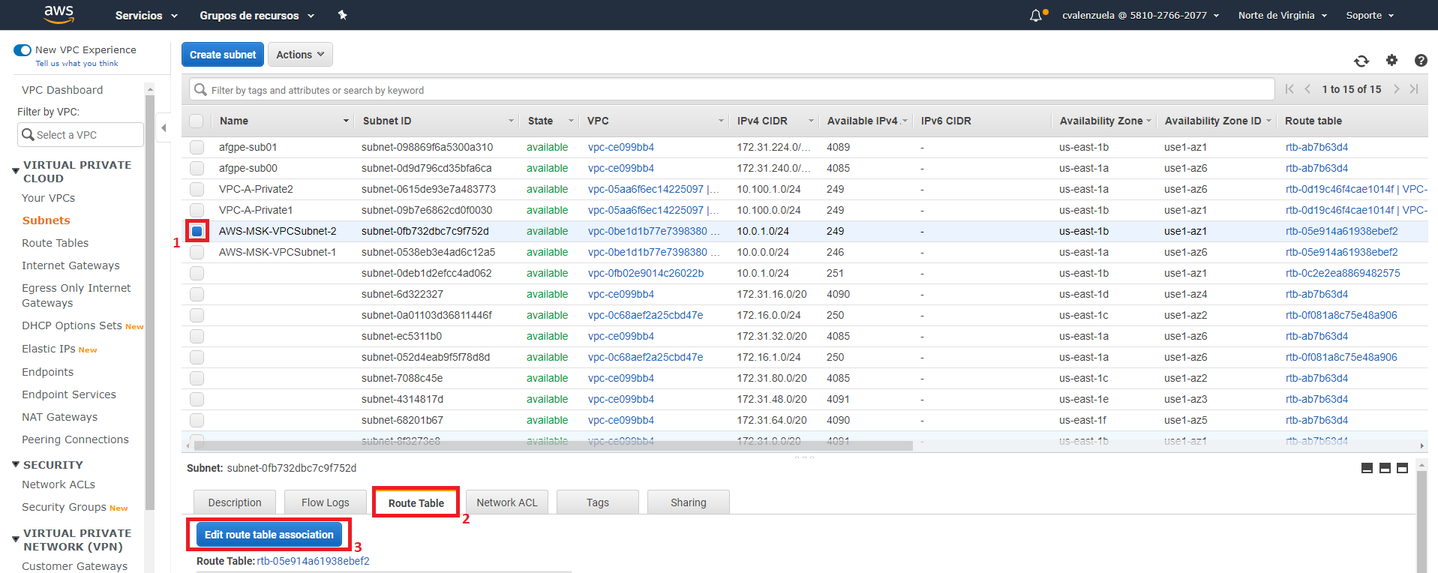
- Paso 12: En la lista Route Table ID (ID de tabla de enrutamiento), elija la tabla de enrutamiento cuyo valor copió anteriormente en este procedimiento.
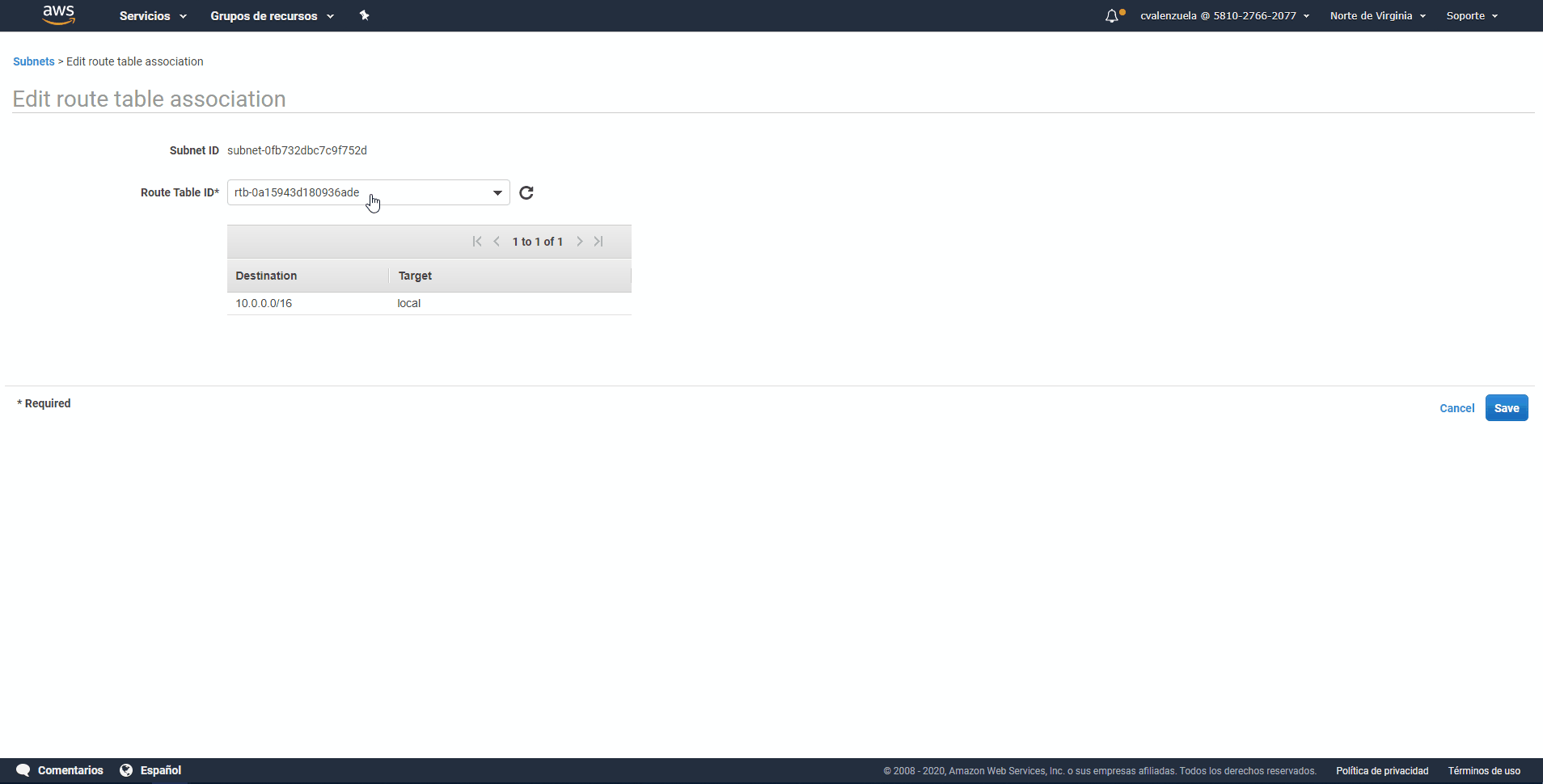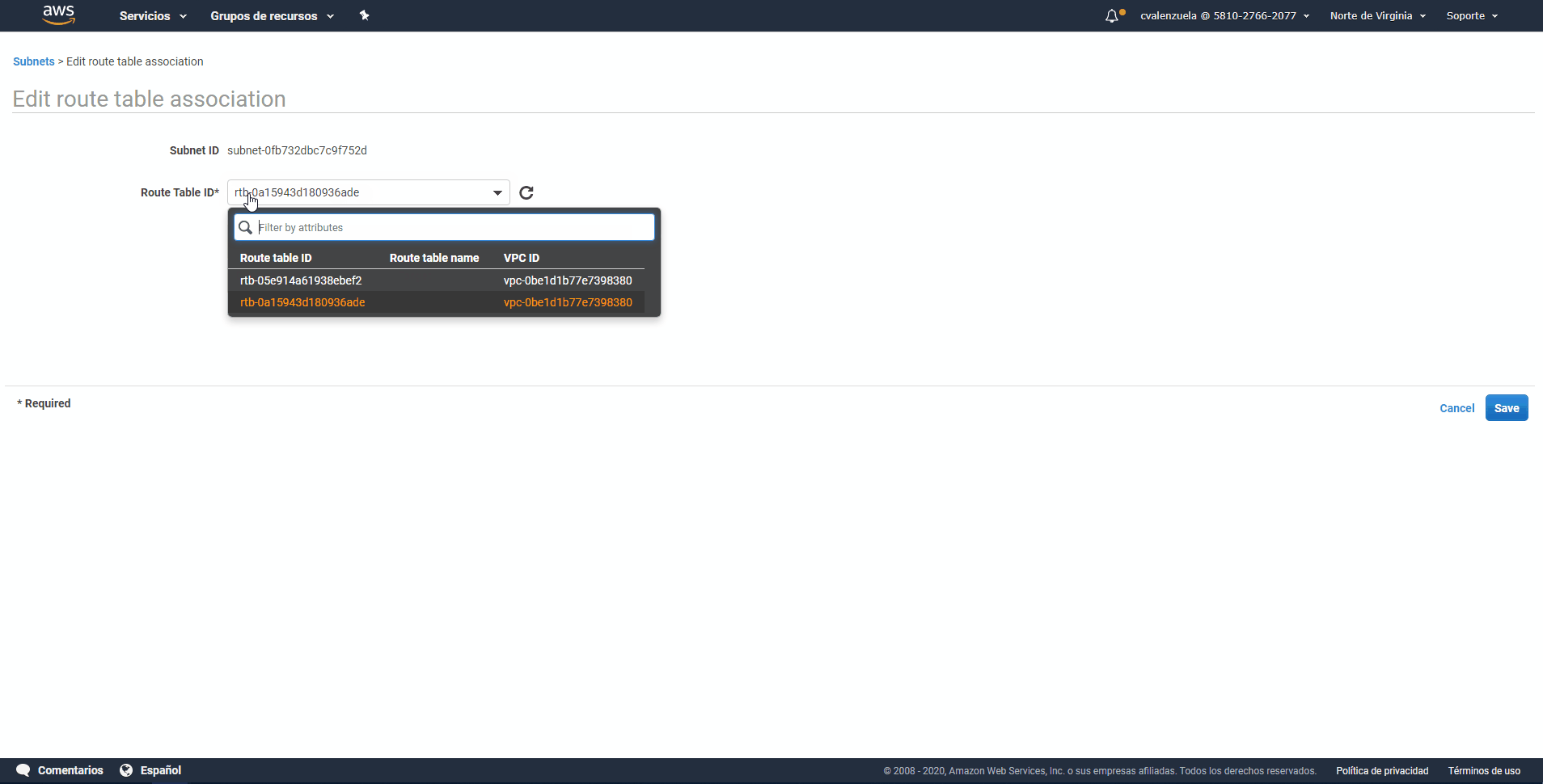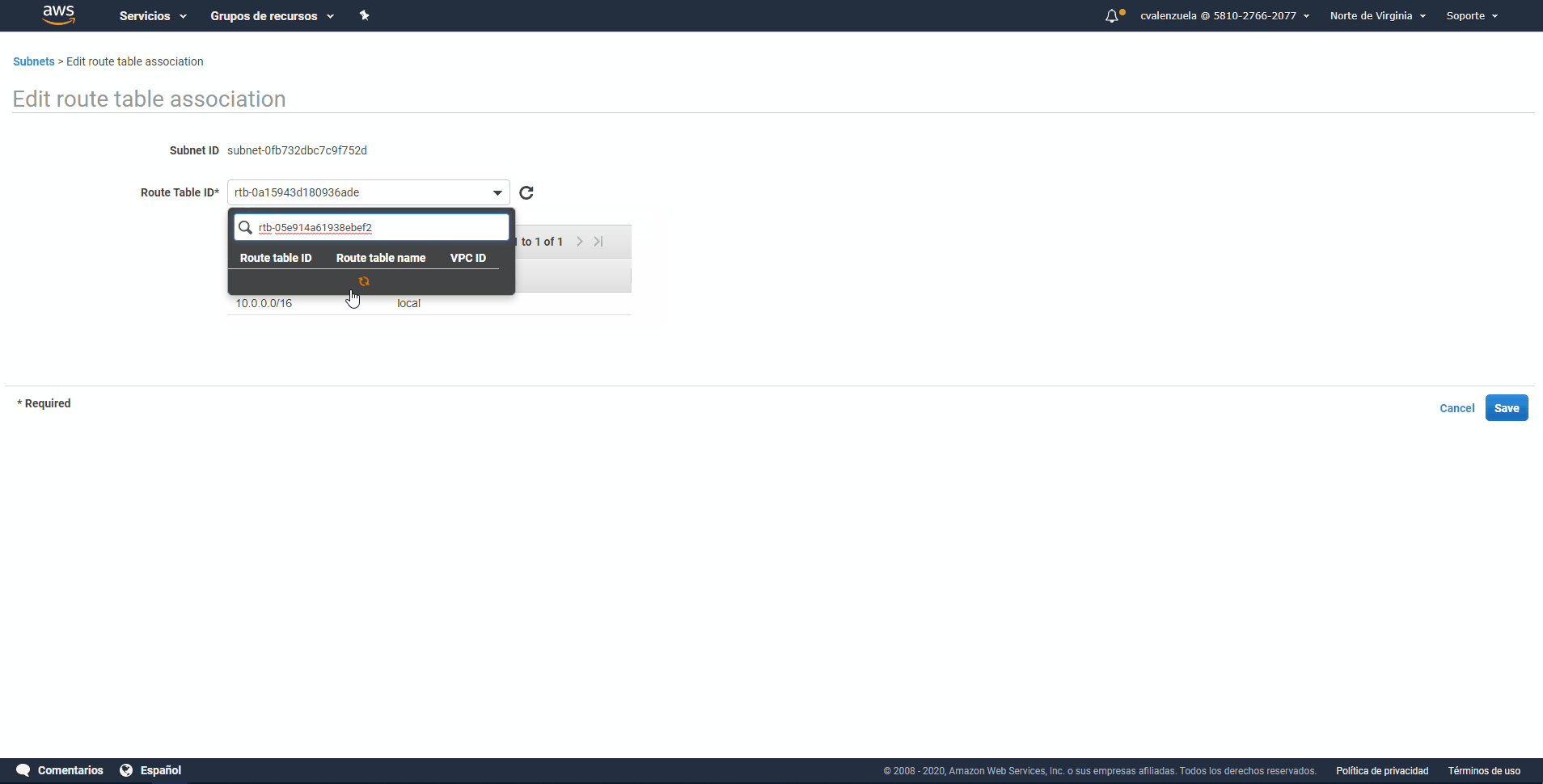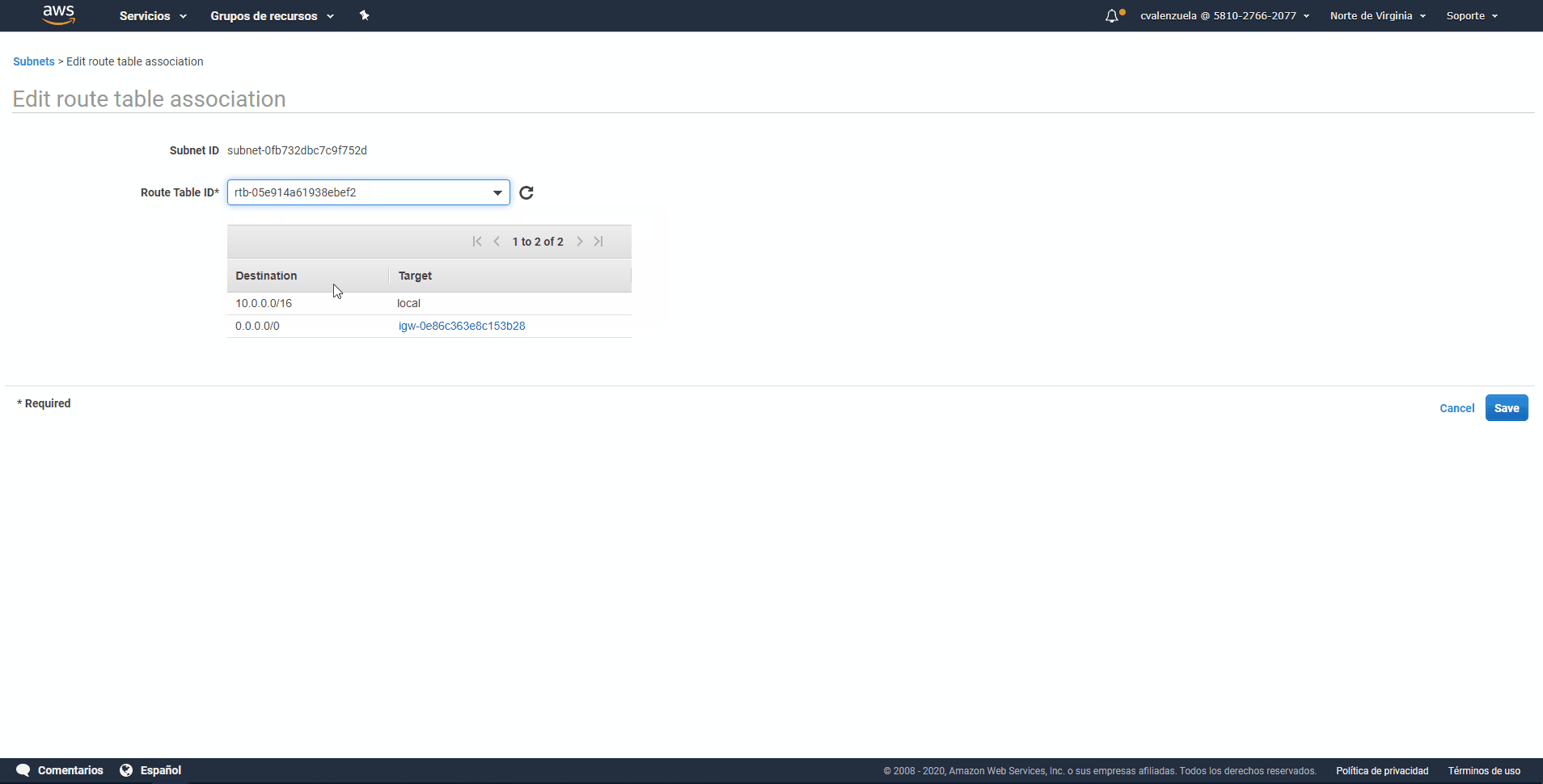
- Paso 13: Elija Save (Guardar) y, a continuación, elija Close (Cerrar).
Si necesita agregar otra subred repita estos pasos cambiando los valores antes agregados
3.3. Creación clúster de MSK
Una vez configurada la VPC en la cual estará alojada el clúster de Amazon MSK, podemos proceder a la creación de este mismo.
Para realizar esta acción debe seguir los siguientes pasos:
- Paso 1: Abra la consola de administración de AWS utilizando sus credenciales de autenticación
- Paso 2: Una vez dentro de la consola seleccione el servicio MSK
- Paso 3: Presionar la opción Create cluster

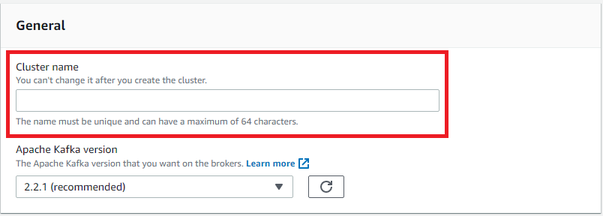
- Paso 4: En el apartado General especificar el nombre (Cluster name) que tendrá el clúster
Ejemplo: kafkfa-test
- Paso 5: En el apartado Networking seleccionar en la opción VPC, la VPC creada con anterioridad.
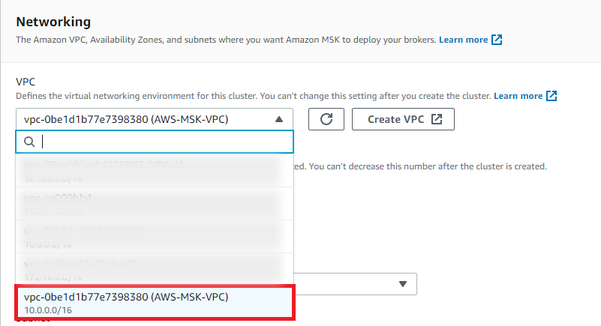
- Paso 6: Una vez seleccionada la VPC, seleccionar las Zona de disponibilidad en las que se desplegará el clúster. Seleccionar dependiendo de las subredes agregadas al VPC.
- Paso 7: Posterior a esto se debe asignar cada subred de la VPC a una zona de disponibilidad distinta de la siguiente manera.
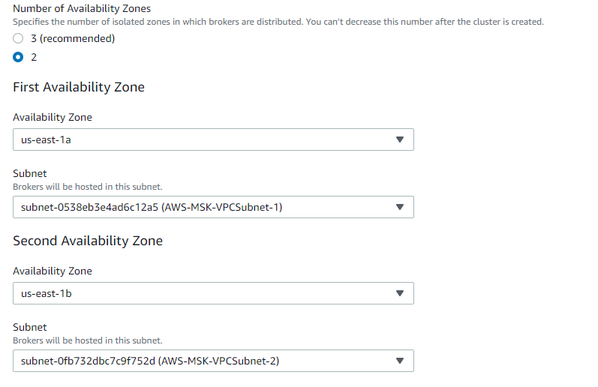
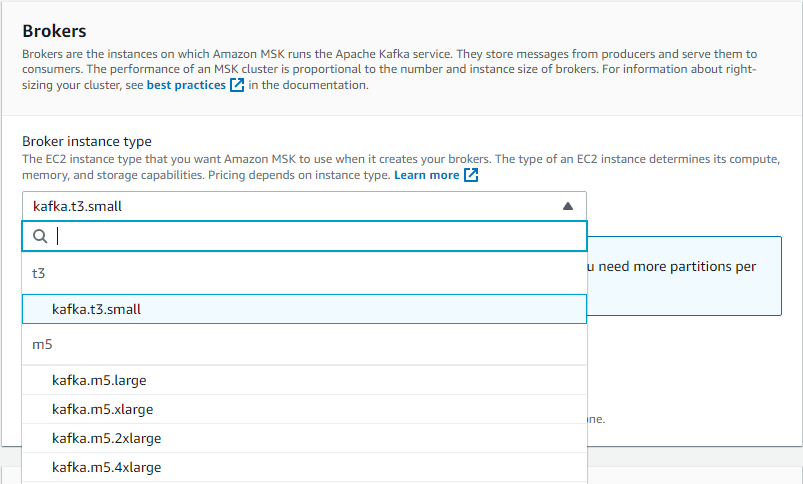
- Paso 8: En el apartado Brokers seleccionar el tipo de instancia en el que se desplegará el cluster, para efectos de este documento se utilizará el tipo t3.small
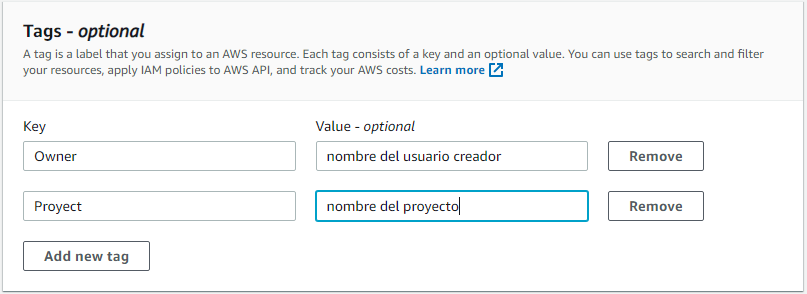
- Paso 9: Para hacer uso de las buenas prácticas de seguridad en AWS se asignaran los siguientes tags al clúster
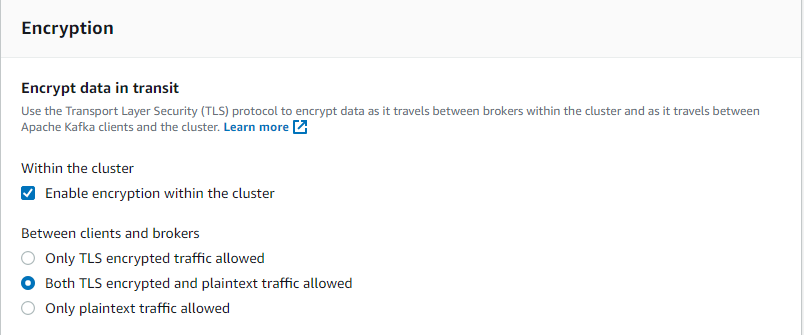
- Paso 10: En el apartado Encryption seleccionar la opción Both TLS encrypted and plaintext traffic allowed para permitir tanto mensajes encriptados como texto plano.
- Paso 11: Finalmente presionar el botón create cluster en la parte inferior de la pantalla para desplegar el clúster. El proceso de creación del clúster tarda aproximadamente 15 minutos.
4. Cliente Amazon MSK
4.1. Creación cliente Amazon MSK
Para poder acceder al cluster se creará una instancia EC2 como cliente de Amazon MSK. Este cliente se utilizará para crear los tópicos y almacenar los servicios que permitirán consumir los datos. Por motivos de simplicidad, pondremos este equipo cliente en la misma VPC que el clúster de Amazon MSK.
Para realizar esta acción se deben realizar los siguientes pasos:
- Paso 1: Abra la consola de Amazon EC2 en https://console.aws.amazon.com/ec2/
- Paso 2: Elija Launch Instance.
- Paso 3: Elija Select (Seleccionar) para crear una instancia de Amazon Linux 2 AMI (HVM), SSD Volume Type (Tipo de volumen SSD).
- Paso 4: Elija el tipo de instancia que alojará el cliente, se recomienda utilizar una que tenga por lo menos 4GB de ram. En este caso se utilizará el tipo t2.medium.
- Paso 5: Elija Next: Configure Instance Details.
- Paso 6: En la lista Network (Red) elija la VPC creada anteriormente.
- Paso 7: En la lista Auto-assign Public IP (Asignar IP pública automáticamente), elija Enable (Habilitar).
- Paso 8: En el menú situado cerca de la parte superior, elija 5. Add Tags (Añadir etiquetas). agregando los mismos tags utilizados al crear el cluster
- Paso 9: Elija Review and Launch (Revisar y lanzar) y, a continuación, elija Launch (Lanzar).
- Paso 10: Elija Create a new key pair (Crear un nuevo par de claves), escriba un nombre para identificar su par de claves en Key pair name (Nombre del par de claves) y elija Download Key Pair (Descargar par de claves). También puede utilizar un par de claves existente si lo prefiere.
4.2. Configuración de cliente Amazon MSK
Una vez creado el cliente para Amazon MSK se debe configurar las reglas del grupo de seguridad para permitir la conexión entre el clúster y el cliente que acabamos de crear.
Para realizar esta acción se deben realizar los siguientes pasos:
- Paso 1: En la consola de Amazon EC2 elegir View Instances (Ver instancias). A continuación, en la columna Security Groups (Grupos de seguridad), elija el grupo de seguridad asociado a la instancia del cliente que se creó recientemente.
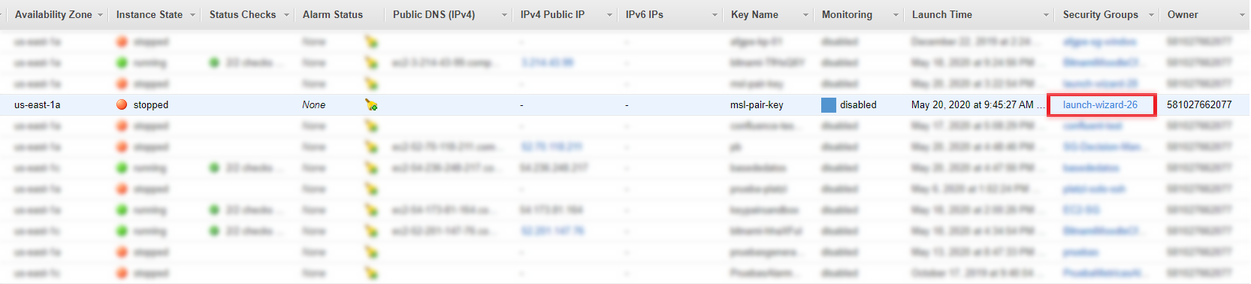
- Paso 2: Copie el valor de Group ID (ID de grupo) asociado al grupo de seguridad y guárdelo para más adelante.
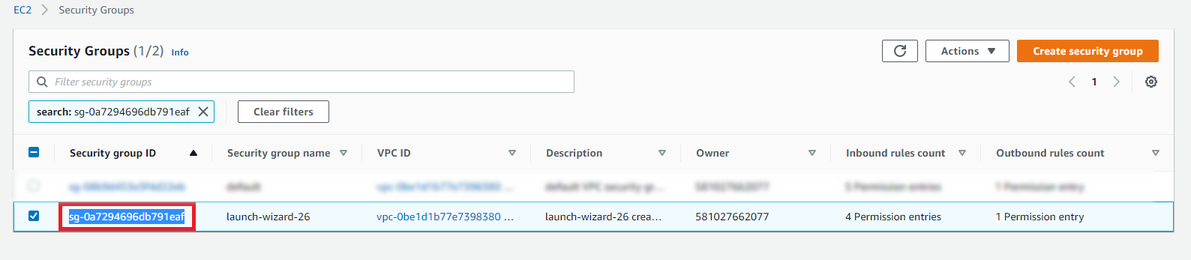
- Paso 3: Abra la consola de Amazon VPC en https://console.aws.amazon.com/vpc/
- Paso 4: En la lista de VPC creados copie el VPC ID asociada a la VPC cread
a al comienzo de este documento.
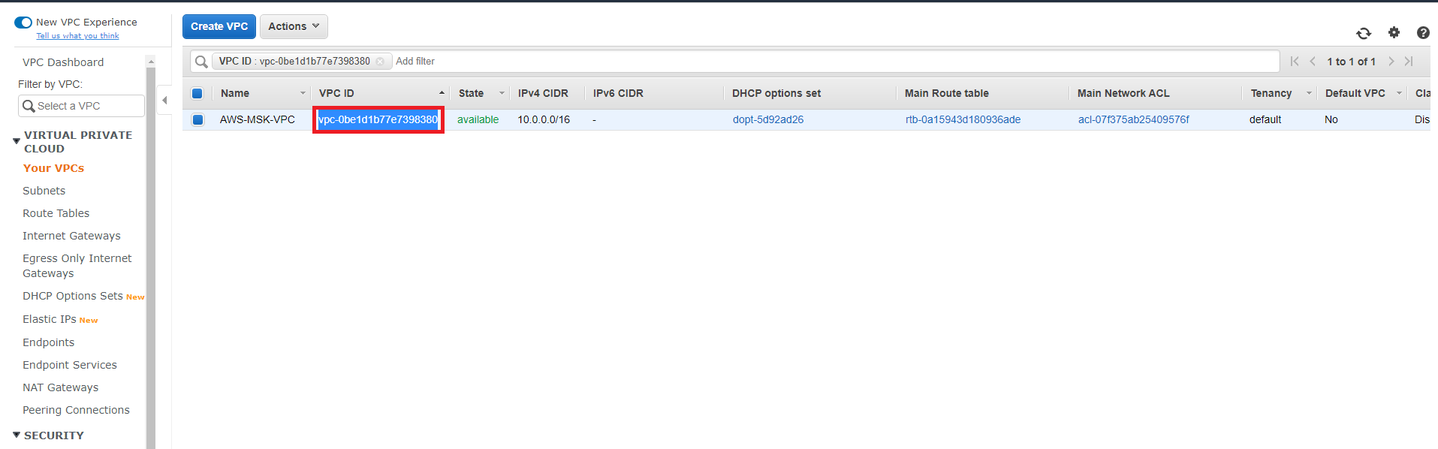
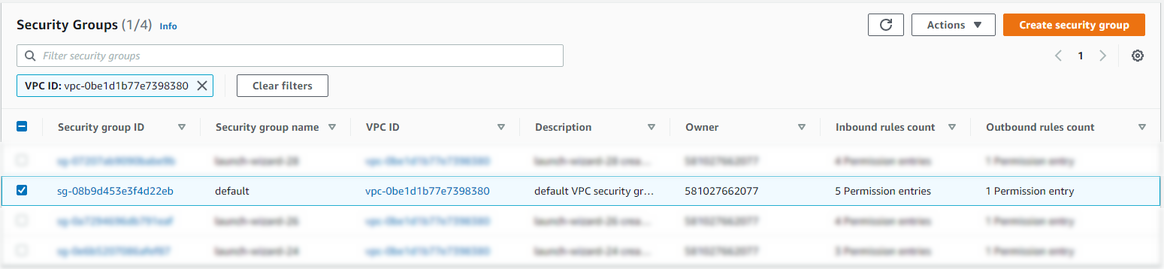
Paso 5: En el apartado Security Groups de la consola Amazon VPC pegue la VPC ID copiada en el paso anterior y péguela en el buscador. Paso 6: Seleccionar el grupo de seguridad por defecto de la VPC
Paso 6: Seleccionar el grupo de seguridad por defecto de la VPC
 Paso 7: En la pestaña Inbound Rules (Reglas de entrada), elija Edit rules (Editar reglas).
Paso 7: En la pestaña Inbound Rules (Reglas de entrada), elija Edit rules (Editar reglas).
 Paso 8: Seleccione Add Rule (Añadir regla).
Paso 8: Seleccione Add Rule (Añadir regla).
Paso 9: En la nueva regla, elija All traffic (Todo el tráfico) en la columna Type (Tipo). En el segundo campo de la columna Source (Origen) escriba el ID del grupo de seguridad del equipo cliente obtenida en el paso 2.
Paso 10: Seleccione Save rules (Guardar reglas).
Repita estos pasos para añadir una regla de entrada en el grupo de seguridad que se corresponda con su equipo cliente para permitir que reciba tráfico del grupo de seguridad del VPC. Ahora su equipo cliente puede comunicarse de manera bidireccional con el Clúster de MSK.
Una vez realizado esto se puede acceder al cliente recién creado y configurado vía ssh.
4.3. Creación de tópicos
Una vez creado el cliente que tiene acceso al clúster de Amazon MSK se procede a crear tópicos a los cuales enviar y consumir mensajes
4.3.1. Pre requisitos.
- Instalar java en el equipo cliente utilizando el siguiente comando:
sudo yum install java-1.8.0
- Descargar y descomprimir Apache Kafka en el equipo cliente:
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
tar -xzf kafka_2.12-2.2.1.tgz
Posteriormente se procede a crear los tópicos siguiendo los siguientes pasos:
- Paso 1: Navegar hasta el directorio de kafka:
cd kafka_2.12-2.2.1
- Paso 2: Obtenga el valor ZookeeperConnectString correspondiente al clúster creado anteriormente para poder crear los tópicos
- Debe configurar sus credenciales de AWS en el cliente utilizando el comando aws configure:
aws kafka describe-cluster –region us-east-1 –cluster-arn «ClusterArn»
El valor ClusterArn se obtiene seleccionando el cluster creado anteriormente desde la consola de Amazon MSK. https://console.aws.amazon.com/msk/
Una vez ingresado el comando anterior obtenemos el siguiente resultado:
{
«ClusterInfo»: {
«EncryptionInfo»: {
«EncryptionInTransit»: {
«ClientBroker»: «TLS_PLAINTEXT»,
«InCluster»: true
},
«EncryptionAtRest»: {
«DataVolumeKMSKeyId»: «arn:aws:kms:us-east-1:581027662077:key/1db13367-6660-4bc8-a575-ffd215041ef1»
}
},
«BrokerNodeGroupInfo»: {
«BrokerAZDistribution»: «DEFAULT»,
«ClientSubnets»: [
«subnet-0538eb3e4ad6c12a5»,
«subnet-0fb732dbc7c9f752d»
],
«StorageInfo»: {
«EbsStorageInfo»: {
«VolumeSize»: 100
}
},
«SecurityGroups»: [
«sg-08b9d453e3f4d22eb»
],
«InstanceType»: «kafka.t3.small»
},
«ClusterName»: «Kafka-test»,
«CurrentBrokerSoftwareInfo»: {
«KafkaVersion»: «2.2.1»
},
«Tags»: {
«owner»: «cvalenzuela»,
«Project»: «poc-kafka»
},
«CreationTime»: «2020-05-15T15:42:33.683Z»,
«NumberOfBrokerNodes»: 2,
«ZookeeperConnectString»: «z-3.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:2181,z-1.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:2181,z-2.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:2181»,
«State»: «ACTIVE»,
«CurrentVersion»: «K3AEGXETSR30VB»,
«ClusterArn»: «arn:aws:kafka:us-east-1:581027662077:cluster/Kafka-test/6fed5882-f025-4369-a775-71be9b525521-5»,
«EnhancedMonitoring»: «DEFAULT»,
«OpenMonitoring»: {
«Prometheus»: {
«NodeExporter»: {
«EnabledInBroker»: false
},
«JmxExporter»: {
«EnabledInBroker»: false
}
}
}
}
}
- Paso 3: Crear el tópico utilizando el siguiente comando:
bin/kafka-topics.sh –create –zookeeper –replication-factor 2 –partitions 1 –topic
Si el comando se ejecuta correctamente, verá el siguiente mensaje: Created topic .
4.4. Producir y consumir datos localmente
Para probar que la conexión hacia clúster y el tópico recién creado sea satisfactoria se realizará una prueba produciendo y consumiendo datos localmente desde el cliente de Amazon MSK.
Para hacer esto se deben seguir los siguientes pasos:
- Paso 1: Obtener la lista de brokers servers a los cuales se enviarán y consumirán los datos:
aws kafka get-bootstrap-brokers –region us-east-1 –cluster-arn
Debe configurar sus credenciales de AWS en el cliente utilizando el comando aws config
El valor ClusterArn se obtiene seleccionando el cluster creado anteriormente desde la consola de Amazon MSK. https://console.aws.amazon.com/msk/
{
«BootstrapBrokerStringTls»: «b-2.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9094,b-1.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9094»,
«BootstrapBrokerString»: «b-2.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9092,b-1.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9092»
}
- Paso 2: Copiar el valor obtenido en para el parámetro BootstrapBrokerString
- Paso 3: Navegar hasta el directorio de kafka:
cd kafka_2.12-2.2.1
- Paso 4: Para producir datos utilizar el siguiente comando:
bin/kafka-console-producer.sh –broker-list –topic
- Paso 5: Abra una nueva consola del cliente de Amazon MSK para poder consumir los datos
- Paso 6: Dentro de la misma carpeta de kafka accedida en el paso 3 utilizar el siguiente comando:
bin/kafka-console-consumer.sh –bootstrap-server –topic –from-beginning
Si todo se ha ejecutado de manera correcta podremos observar que al escribir un mensaje desde la consola del productor (izquierda) se replica hacia la consola del consumidor (derecha).
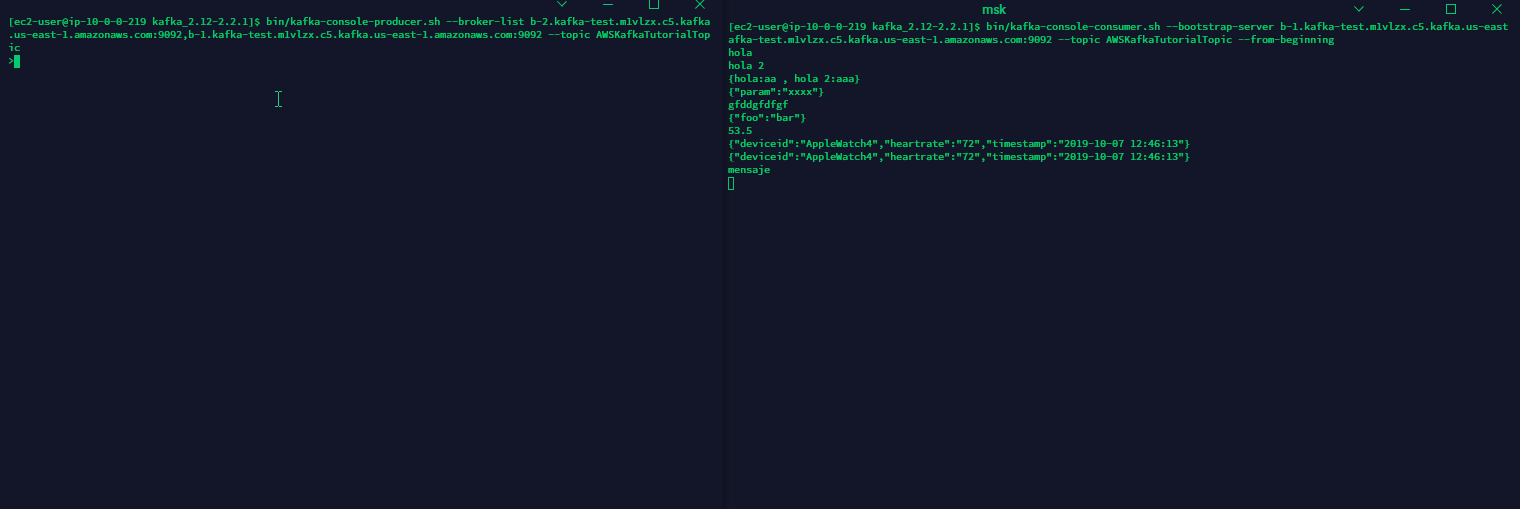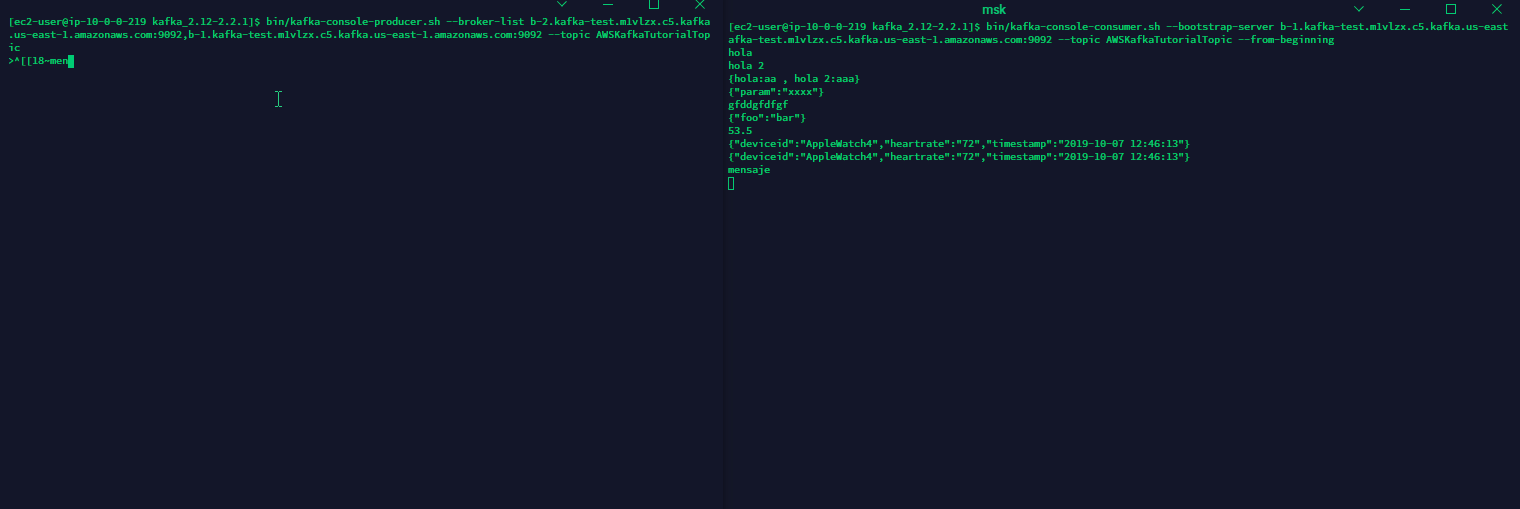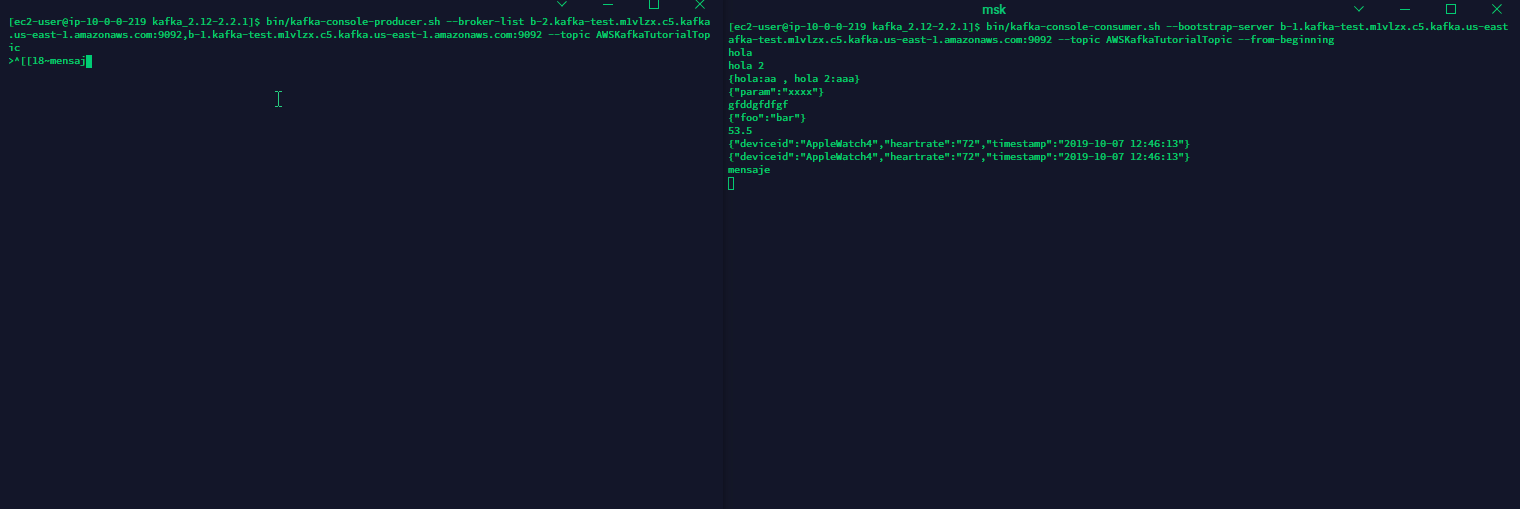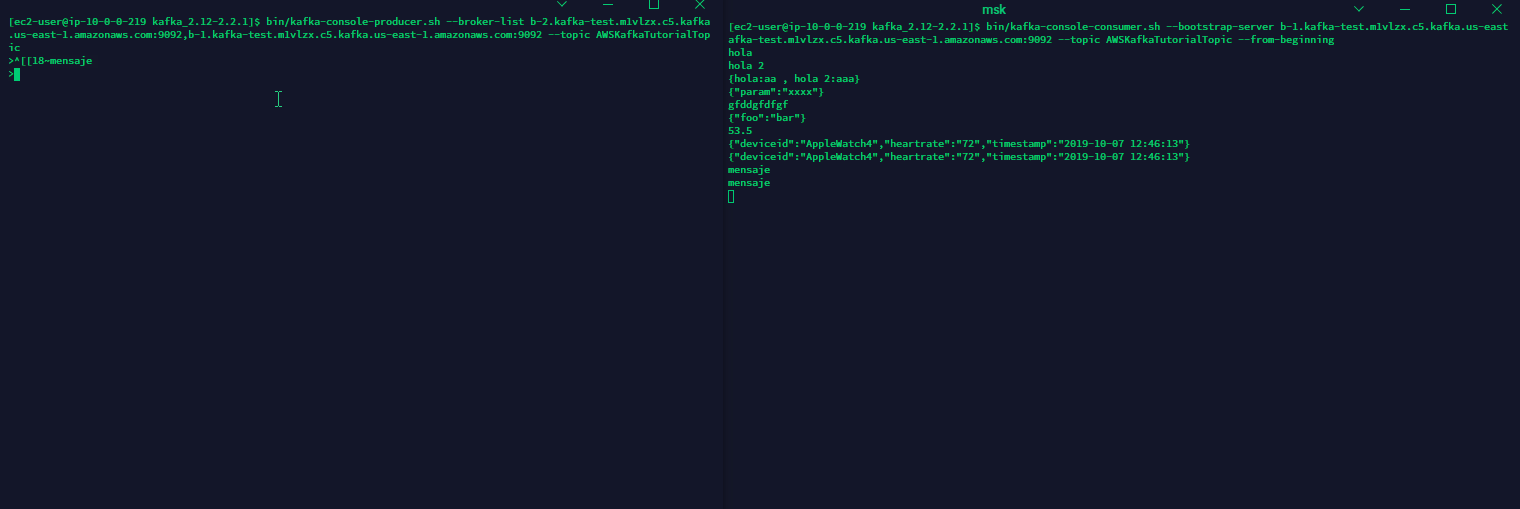
5. Productor de datos
Una vez creado el clúster y el tópico de Apache Kafka utilizando Amazon MSK, se procede a configurar el productor de datos que es el que se encargará de enviar los mensajes hacia el clúster. Para hacer esto se utilizara Attunity Replicate ya que nos permite la ingesta de datos desde múltiples fuentes hacia un tópico en específico de Apache Kafka.
5.1. Instalación Attunity Replicate
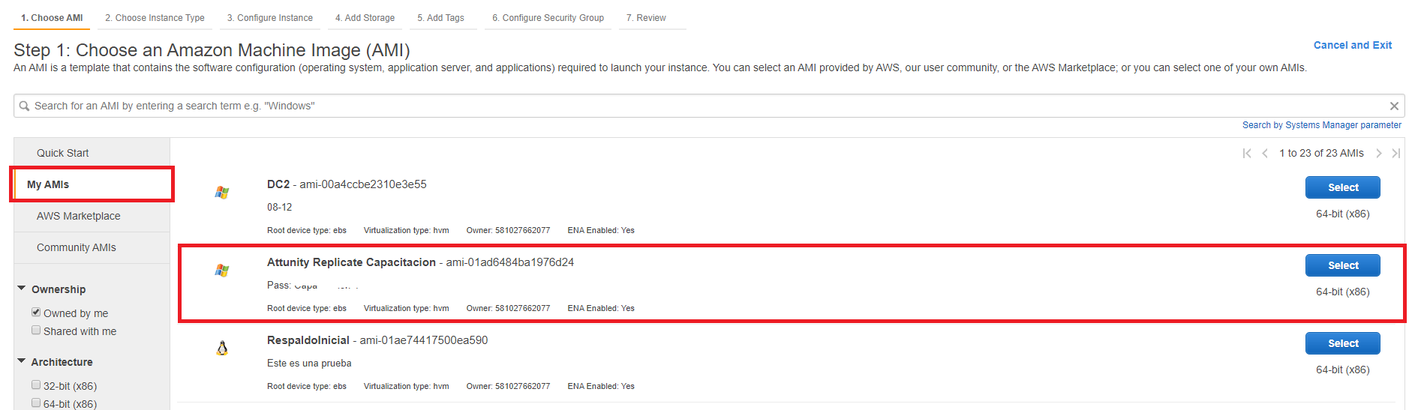
Para la instalación de esta herramienta se puede utilizar una imagen AMI con Attunity previamente instalado, por lo que sólo se debe crear la instancia EC2 correspondiente a esta herramienta. En este caso se llama Attunity Replicate Capacitacion y es una instancia windows por lo que una vez creada se puede acceder a esta mediante windows remote.
Se creará esta instancia dentro del VPC donde se encuentra el cluster, por lo que se debe configurar eso al momento de crear la imagen de la herramienta. Para hacer esto se deben realizar los siguientes pasos:
- Paso 1: Abra la consola de Amazon EC2 en https://console.aws.amazon.com/ec2/
- Paso 2: Elija Launch Instance.
- Paso 3: Seleccionar la imagen Attunity Replicate Capacitacion dentro del menú de My AMIs

- Paso 4: Elija el tipo de instancia que aloja la imagen de Attunity Replicate, se recomienda utilizar una que tenga por lo menos 4GB de ram. En este caso se utilizará el tipo t2.medium.
- Paso 5: Elija Next: Configure Instance Details.
- Paso 6: En la lista Network (Red) elija la VPC creada en el paso “Crear una VPC para el clúster de MSK” de este mismo documento.
- Paso 7: En la lista Auto-assign Public IP (Asignar IP pública automáticamente), elija Enable (Habilitar).
- Paso 8: En el menú situado cerca de la parte superior, elija 5. Add Tags (Añadir etiquetas). agregando los mismos tags utilizados al crear el cluster
- Paso 9: Elija Review and Launch (Revisar y lanzar) y, a continuación, elija Launch (Lanzar).
- Paso 10: Elija Create a new key pair (Crear un nuevo par de claves), escriba un nombre para identificar su par de claves en Key pair name (Nombre del par de claves) y elija Download Key Pair (Descargar par de claves). También puede utilizar un par de claves existente si lo prefiere.
5.2. Configuración Attunity Replicate
Una vez creada la instancia que contiene Attunity Replicate se debe configurar las reglas del grupo de seguridad para permitir la conexión entre el clúster y Attunity Replicate.
Para realizar esta acción se deben realizar los siguientes pasos:
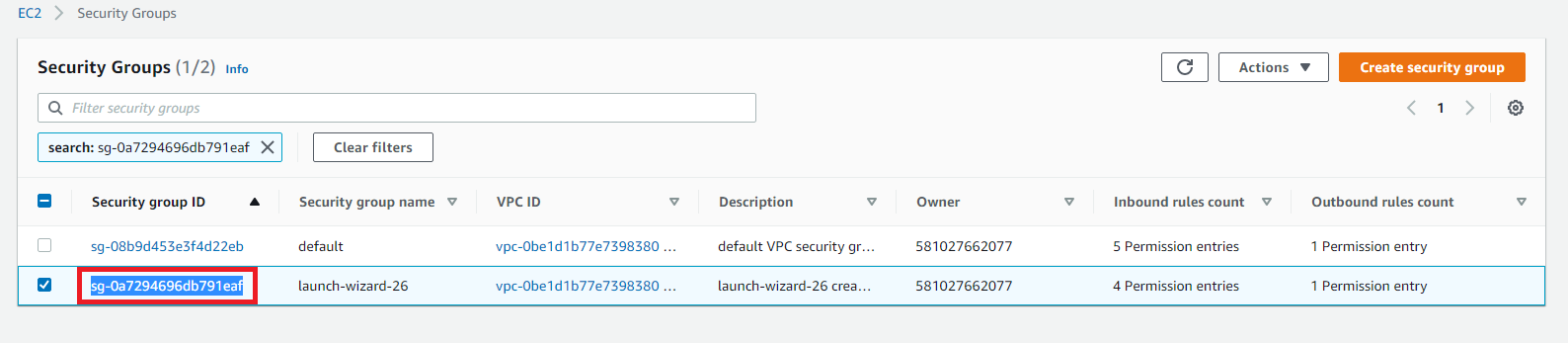
- Paso 1: En la consola de Amazon EC2 elegir View Instances (Ver instancias). A continuación, en la columna Security Groups (Grupos de seguridad), elija el grupo de seguridad asociado a la instancia que contiene Attunity Replicate que se creó recientemente.
- Paso 2: Copie el valor de Group ID (ID de grupo) asociado al grupo de seguridad y guárdelo para más adelante.
- Paso 3: Abra la consola de Amazon VPC en https://console.aws.amazon.com/vpc/
- Paso 4: En la lista de VPC creados copie el VPC ID asociada a la VPC creada al comienzo de este documento.
- Paso 5: En el apartado Security Groups de la consola Amazon VPC pegue la VPC ID copiada en el paso anterior y péguela en el buscador.
- Paso 6: Seleccionar el grupo de seguridad por defecto de la VPC
- Paso 7: En la pestaña Inbound Rules (Reglas de entrada), elija Edit rules (Editar reglas).
- Paso 8: Seleccione Add Rule (Añadir regla).
- Paso 9: En la nueva regla, elija All traffic (Todo el tráfico) en la columna Type (Tipo). En el segundo campo de la columna Source (Origen) escriba el ID del grupo de seguridad de la instancia de Attunity Replicate obtenida en el paso 2.
- Paso 10: Seleccione Save rules (Guardar reglas).
Repita estos pasos para añadir una regla de entrada en el grupo de seguridad que se corresponda con la instancia de Attunity Replicate para permitir que reciba tráfico del grupo de seguridad del VPC. Ahora su instancia de Attunity Replicate puede comunicarse de manera bidireccional con el Clúster de MSK.
Una vez realizado esto se puede acceder a la instancia mediante windows remote.
5.3. Acceso a Attunity Replicate
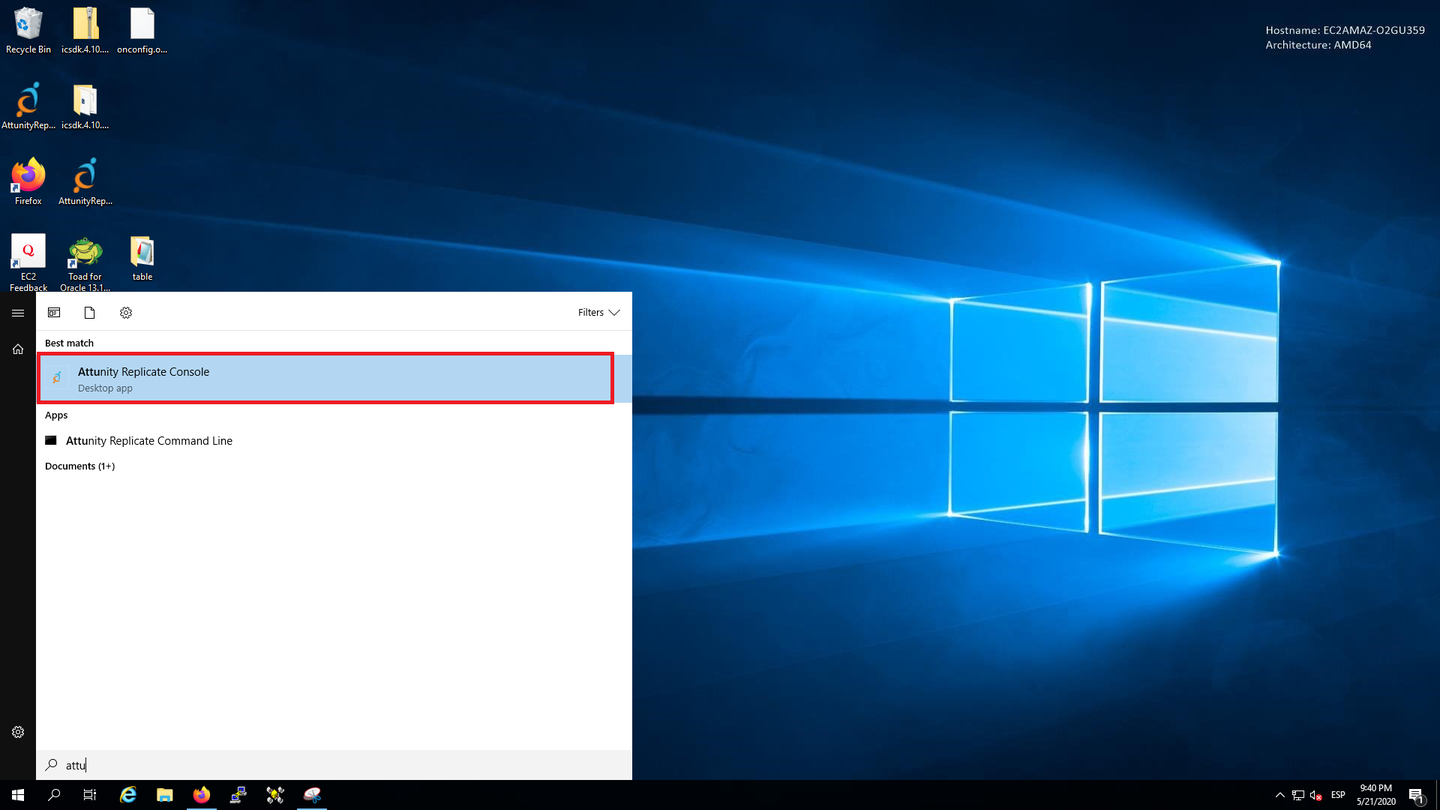
Una vez ingresado a la instancia EC2 de Attunity Replicate para acceder a la herramienta se debe buscar Attunity Replicate Console desde el buscador de aplicaciones de windows.
5.4. Configuración de conectores
Attunity Replicate permite acceder o enviar datos mediante conectores que pueden ser de tipo source o tipo target.
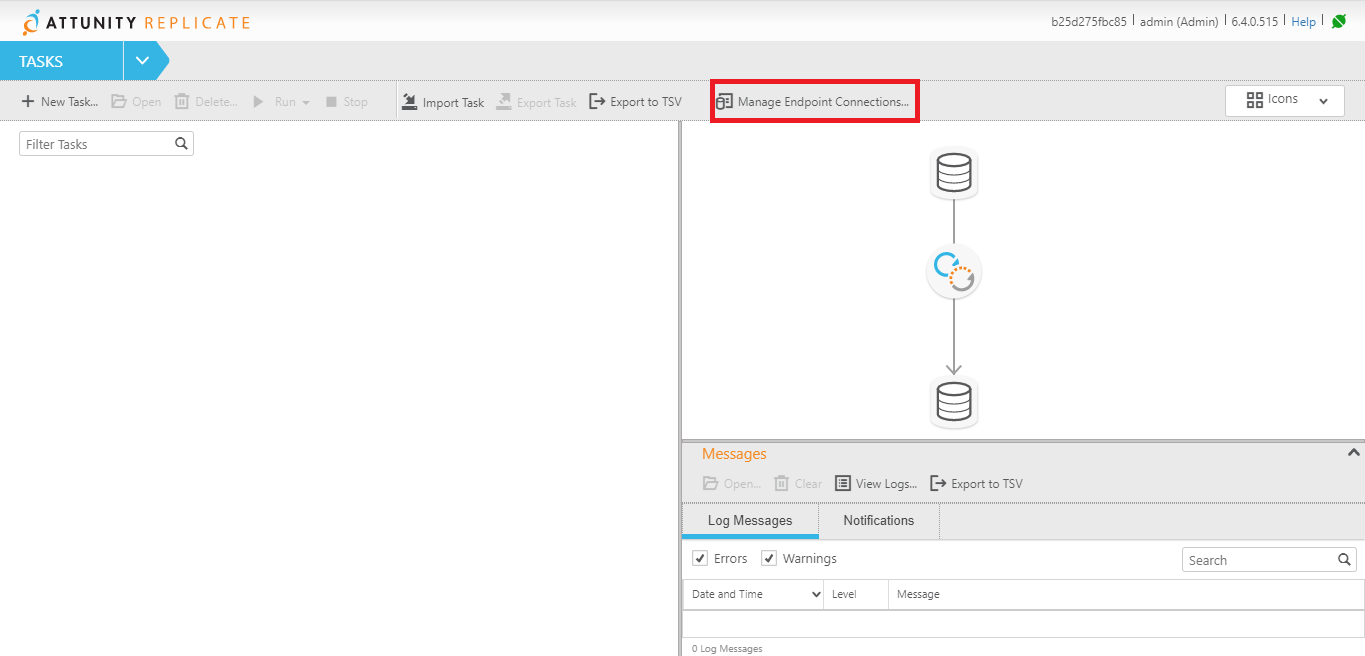
Para manejar estos conectores seleccionar la siguiente opción:
5.4.1. Configurar source connector
Este tipo de conectores permiten obtener la información desde diferentes fuentes. Los tipo soportados por los conectores source de Attunity son:
- Amazon RDS for MySQL
- Amazon RDS for PostgreSQL
- Amazon RDS for SQL Server
- DISAM (ARC)
- File
- File Channel
- Google Cloud SQL for MySQL
- Google Cloud SQL for PostgreSQL
- HP NonStop Enscribe (AIS)
- HP NonStop SQL/MP (AIS)
- Hadoop
- IBM DB2 for LUW
- IBM DB2 for iSeries
- IBM DB2 for z/OS
- IBM IMS (ARC)
- Microsoft Azure SQL Managed Instance
- Microsoft SQL Server
- MySQL
- ODBC
- ODBC with CDC
- Oracle
- PostgreSQL
- RMS (ARC)
- SAP Application
- SAP Application (DB)
- SAP HANA
- SAP Sybase ASE
- Teradata Database
- VSAM (ARC)
Para crear un conector de tipo source se deben seguir los siguientes pasos:
Una vez dentro de la pestaña de Manage Endpoint Connections que es de donde se manejan los conectores seleccionar New Endpoint Connection
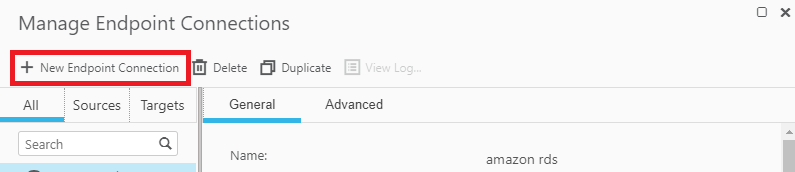
Seleccionar tipo source en el checkbox de role y completar datos del conector según el tipo de este.
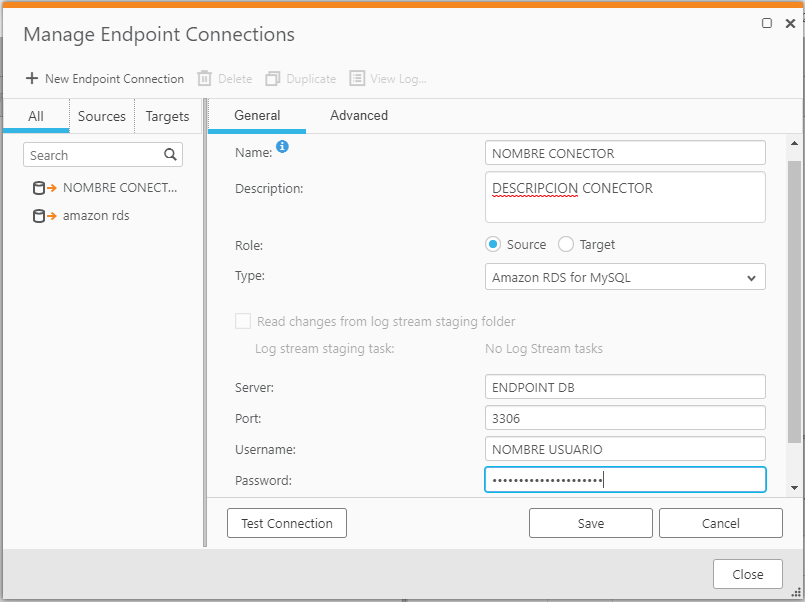
A modo de ejemplo se crea conector source de tipo Amazon RDS for MySQL
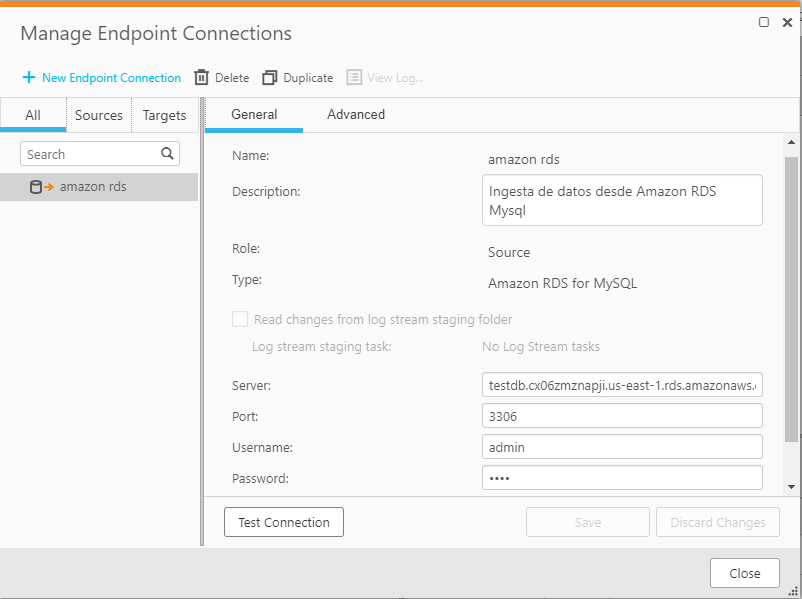
Los datos de origen corresponden a una base de datos que contiene información de ciudades del mundo, recopilados en el siguiente enlace https://dev.mysql.com/doc/index-other.html
Finalmente se prueba que la conexión al conector sea realizada con éxito y se guarda el conector presionando save
5.4.2. Configurar target connector
Este tipo de conectores permiten enviar la información de un source hacia otro tipo de aplicación. Los tipo soportados por los conectores target de Attunity son:
- Actian Vector
- Amazon EMR
- Amazon Kinesis Data Streams
- Amazon Redshift
- Amazon S3
- File
- File Channel
- Google Cloud SQL for MySQL
- Google Cloud SQL for PostgreSQL
- Google Cloud Storage
- Google Dataproc
- HP Vertica
- Hadoop
- Hortonworks Data Platform (HDP)
- Kafka
- Log Stream
- MapR Streams
- MemSQL
- Microsoft Azure ADLS
- Microsoft Azure Database for MySQL
- Microsoft Azure Database for PostgreSQL
- Microsoft Azure Databricks
- Microsoft Azure HDInsight
- Microsoft Azure SQL Database
- Microsoft SQL Server
- MySQL
- ODBC
- Oracle
- Pivotal Greenplum
- PostgreSQL
- SAP HANA
- Snowflake on AWS
- Snowflake on Azure
- Teradata Database
Para crear un conector de tipo target se deben seguir los siguientes pasos:
Una vez dentro de la pestaña de Manage Endpoint Connections que es de donde se manejan los conectores seleccionar New Endpoint Connection
Seleccionar tipo target en el checkbox de role y completar datos del conector según el tipo de este.
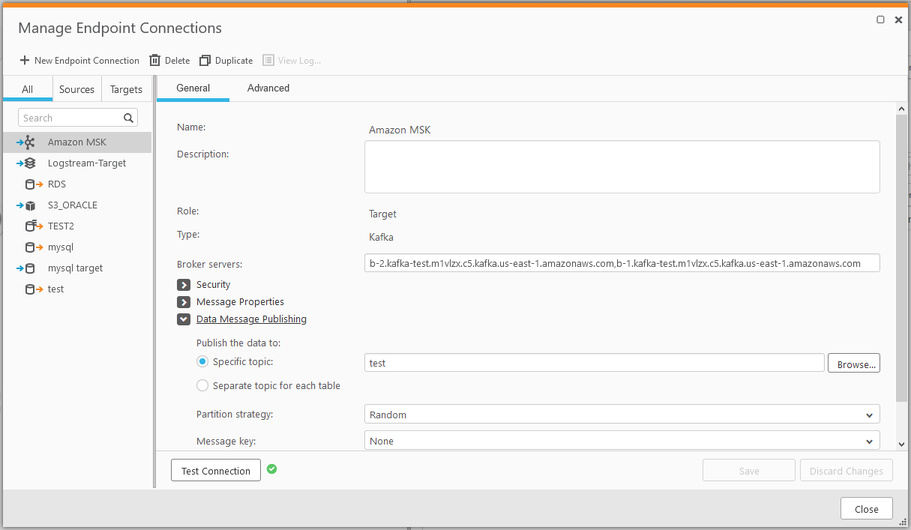
IMPORTANTE: recordar que el broker servers es donde está alojado el cluster, en este caso es el valor BootstrapBrokerString obtenido en el paso 1 del apartado “Producir y consumir datos localmente” de este mismo documento.
- Agregar el valor BootstrapBrokerString quitando los puertos
- Posteriormente en el apartado data message publishing se selecciona el tópico al que se suscribirá el conector, en este caso el tópico seleccionado fue test
- Finalmente se prueba que la conexión al conector sea realizada con éxito y se guarda el conector presionando save.
5.5. Tasks
Attunity Replicate permite replicar datos desde un punto de origen hacia un punto objetivo. Para realizar esto se utilizan las tareas o task. Cada tarea tiene un punto de origen (Conector Source) y punto objetivo (Conector target).
5.5.1. Creation of Tasks
Para crear una nueva tarea se debe presionar la opción New Task desde la pantalla principal, como se muestra a continuación.
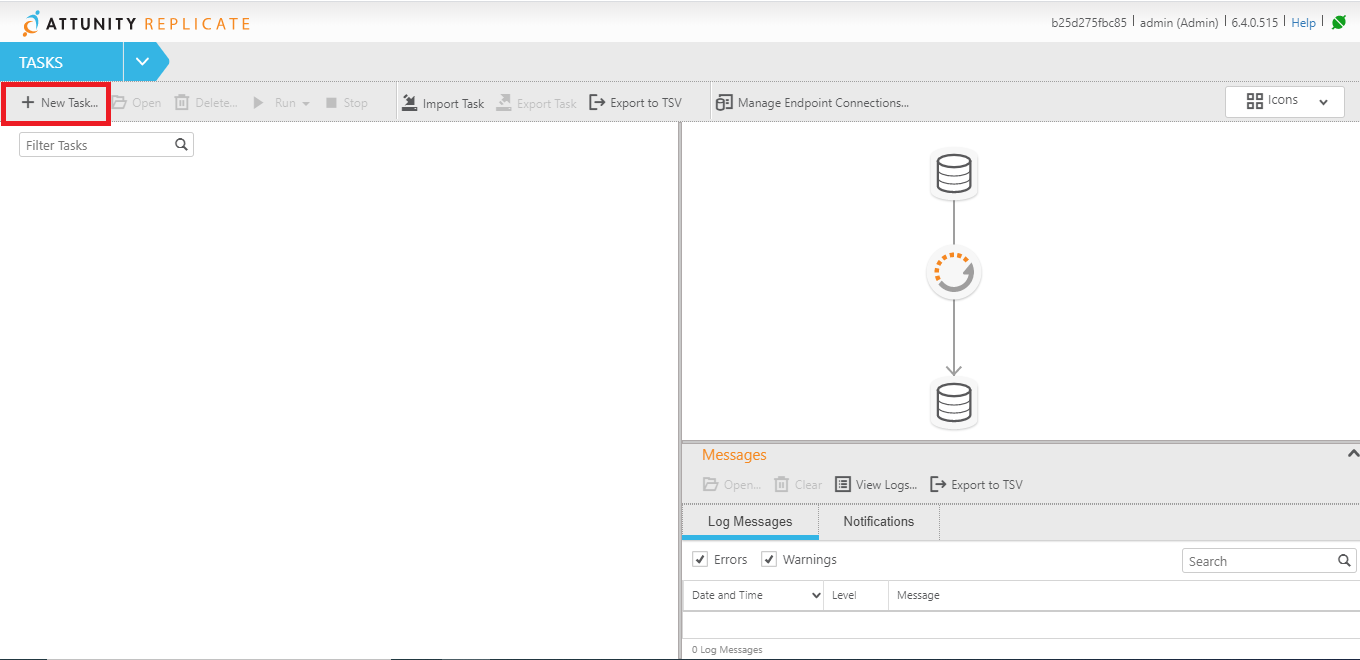 Posterior a esto se deben especificar el nombre y la descripción del task que debe considerar la acción que realizará ese caso de uso de replicate.
Posterior a esto se deben especificar el nombre y la descripción del task que debe considerar la acción que realizará ese caso de uso de replicate.
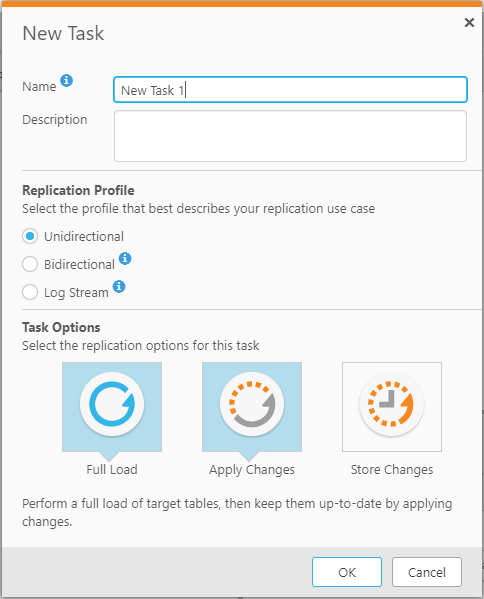
También se debe configurar el Replication Profile que describa a la tarea a realizar. hay 3 tipos de replication profile, los cuales son :
- Unidirectional: para replicar entre los puntos finales para el propósito de Unidireccional
- Bidirectional: para sincronizar los registros entre dos puntos finales.
- Log Stream: permite una tarea de replicación dedicada a guardar los cambios de datos del registro de transacciones de una base de datos de una sola fuente y aplicarlos a múltiples objetivos, sin la sobrecarga de tener que leer los registros de cada objetivo por separado.
Finalmente se configuran las opciones del task donde se eligen al menos una de las opciones que se presentan, las cuales son:
- Full load: Cuando se activa la carga completa, Replicate carga los datos de la fuente inicial al punto final del objetivo.
- Apply Changes: Attunity Replicate procesa los cambios. Por defecto, el procesamiento de las modificaciones se lleva a cabo para esta tarea. Se puede visualizar el procesamiento de la modificación en la vista del monitor.
- Store Changes: Los cambios se almacenan en tablas de cambio o en una tabla de auditoría. Por defecto, los cambios no se almacenan.
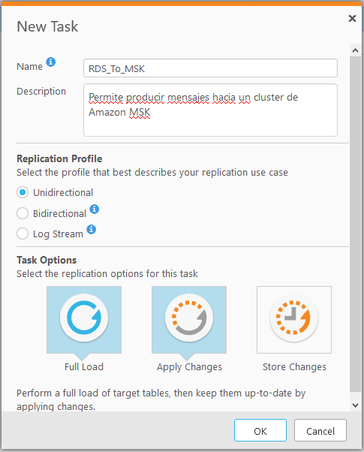
En este caso en particular se selecciona el replication pr
ofile Unidirectional ya que solo se requiere enviar datos hacia un punto final y en task options se seleccionan Full Load para realizar una carga inicial de datos y Apply Changes para enviar datos a medida que los registros de la base de datos cambian, quedando de la siguiente manera.
5.5.2. Configuración de Tarea
Una vez creada la tarea se debe configurar para su funcionamiento.
Como primer paso se deben asignar los conectores que se utilizarán en la tarea, esto se hace arrastrándolos hacia su posición dentro de la tarea de la siguiente forma.
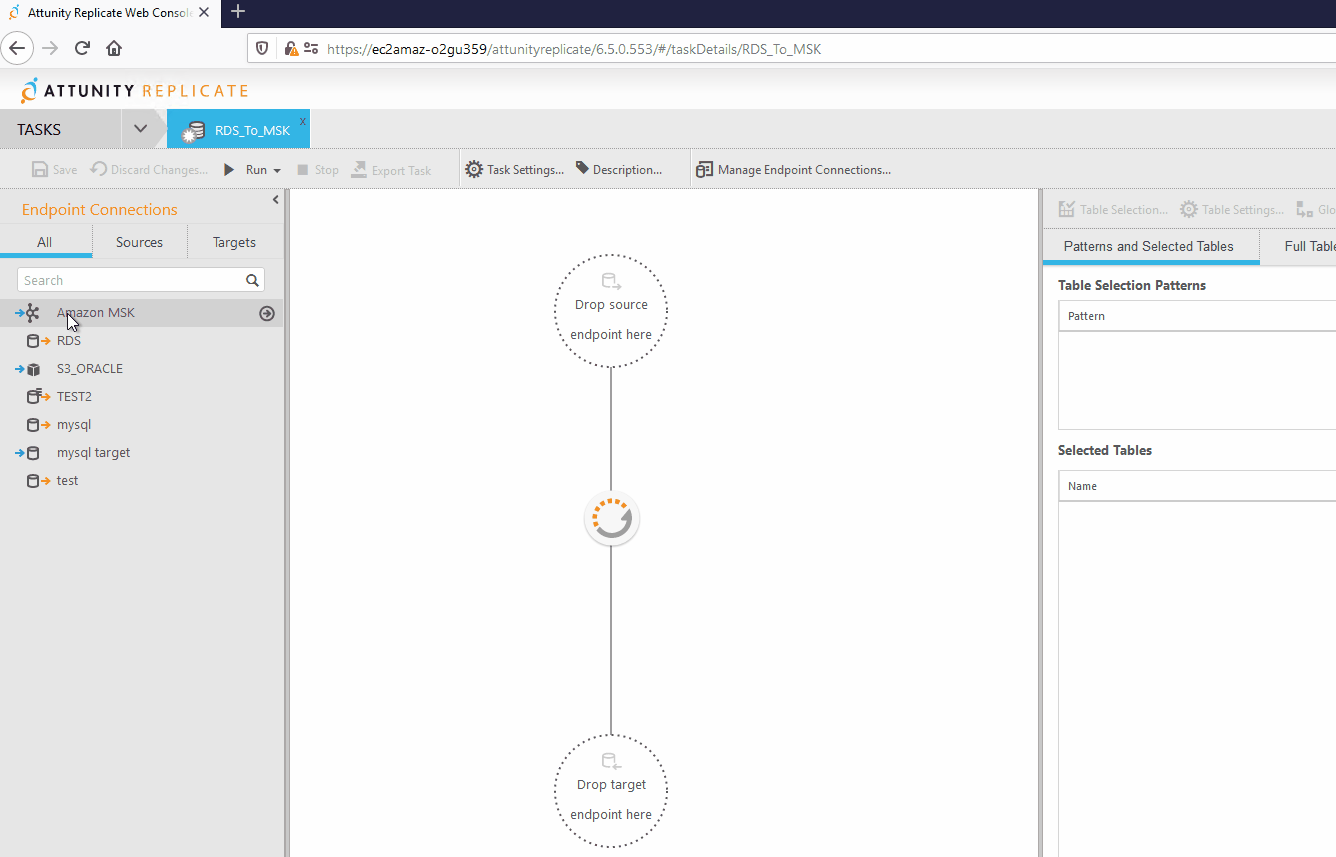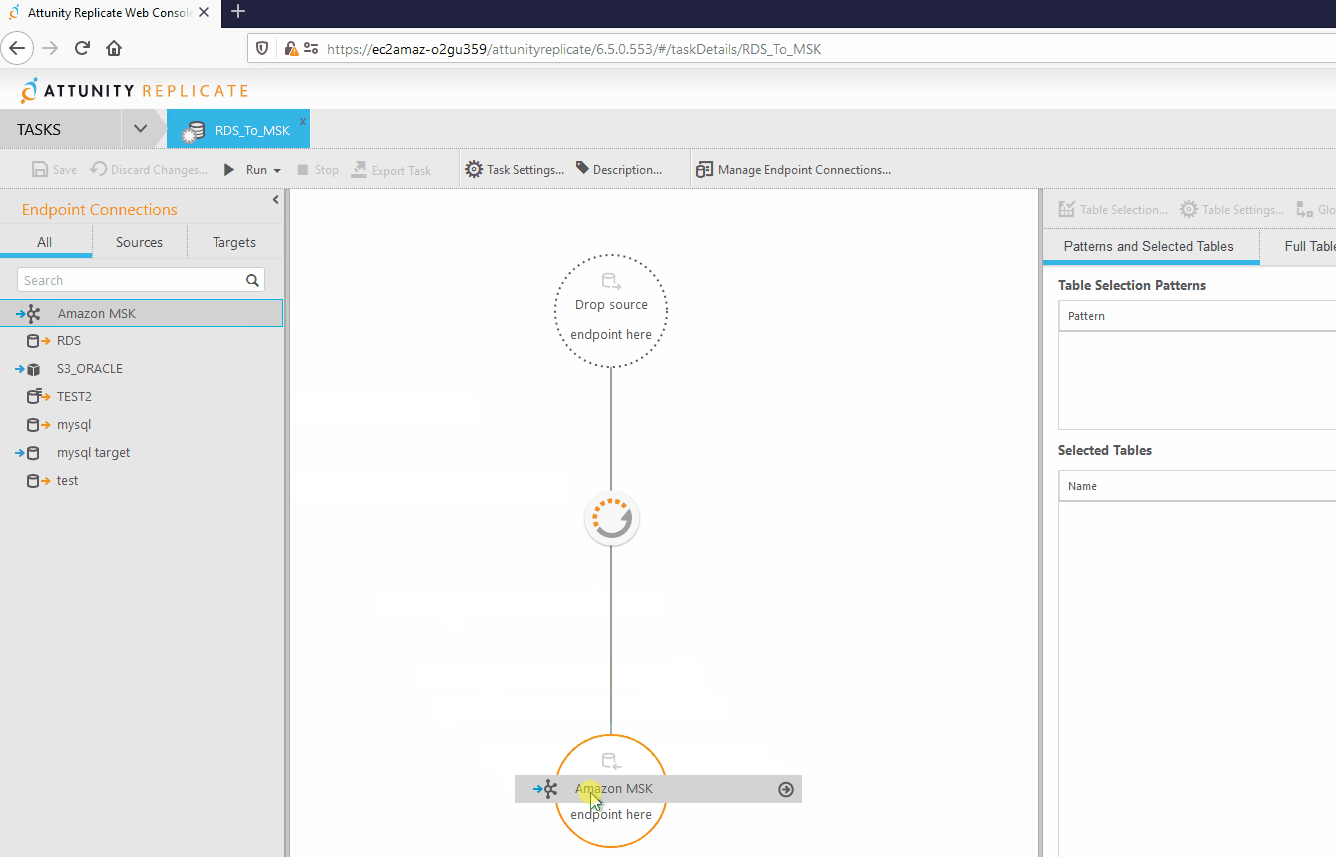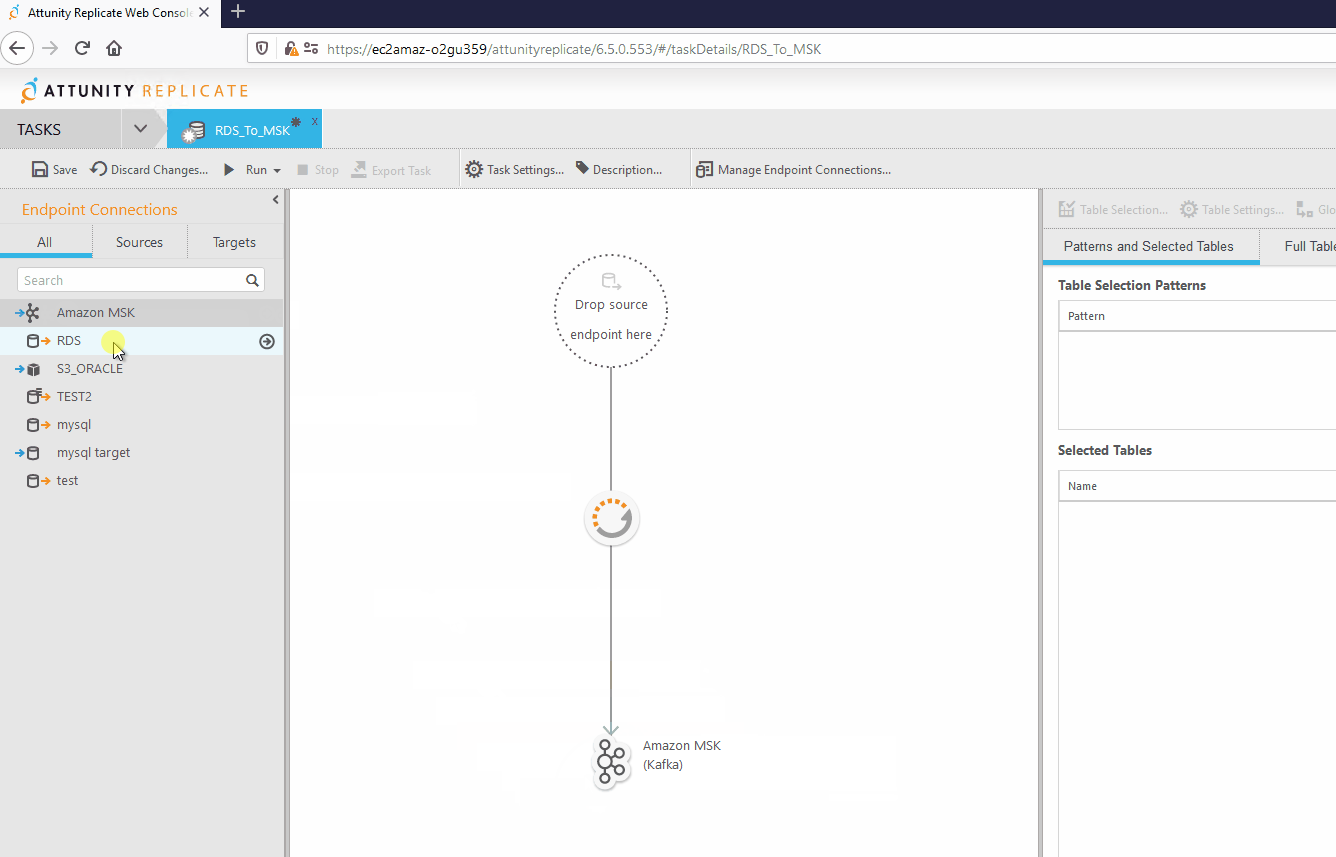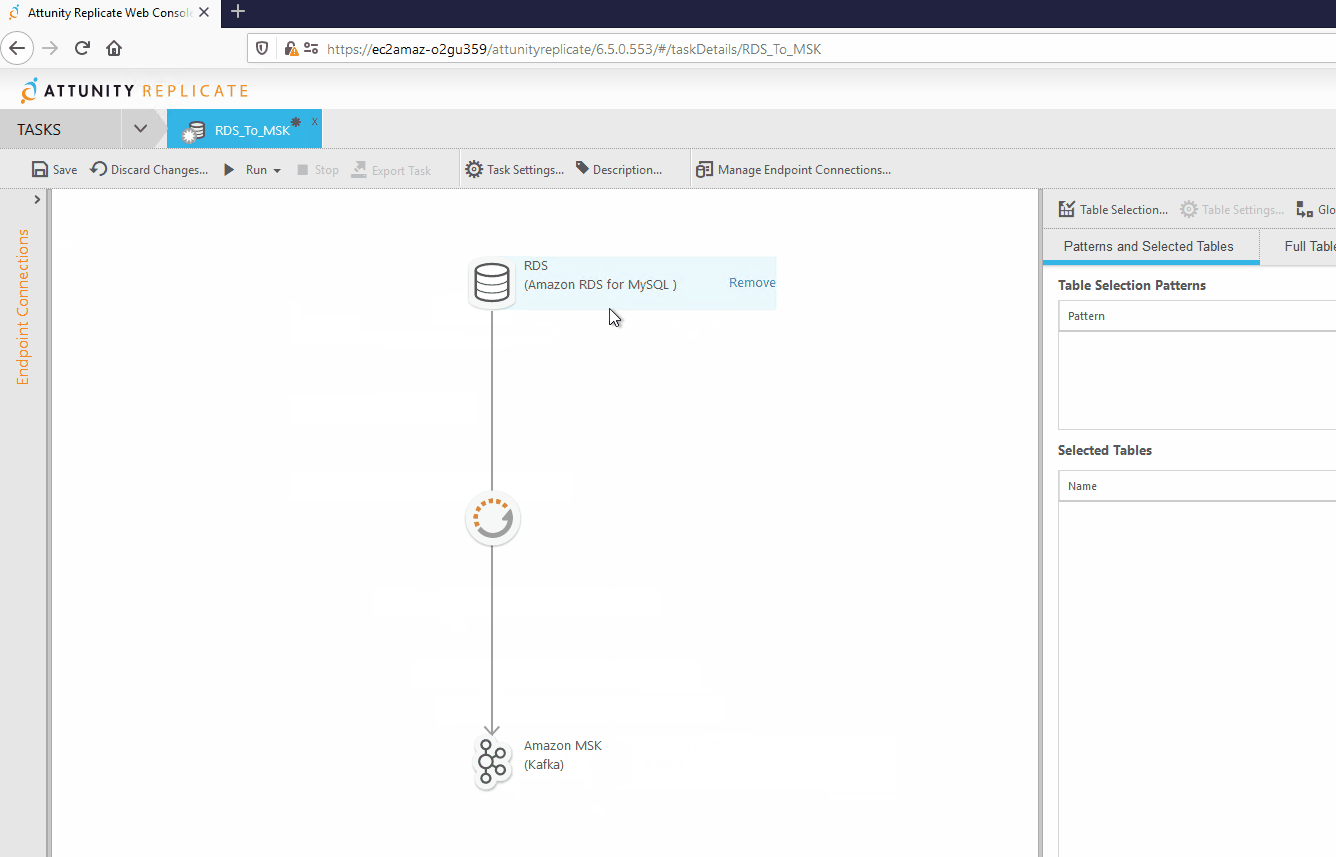
Posterior a esto se seleccionan las tablas a replicar hacia el destino seleccionado.
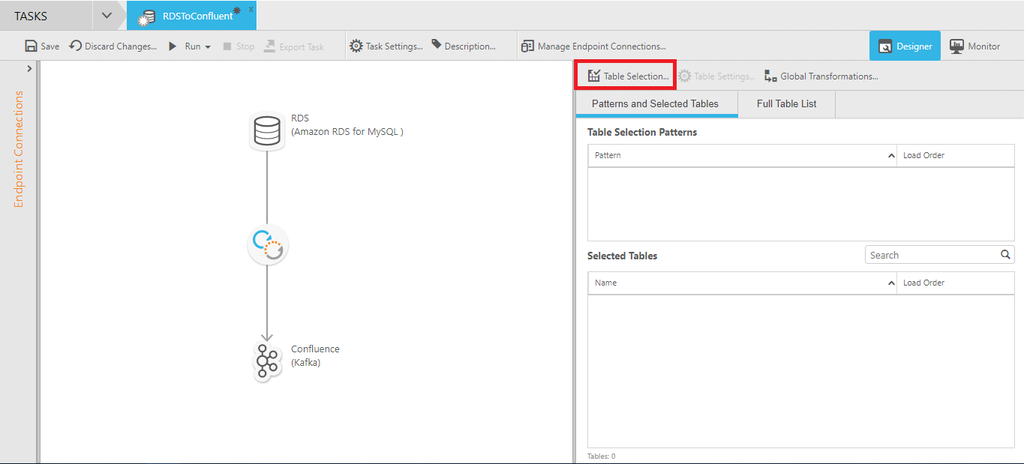
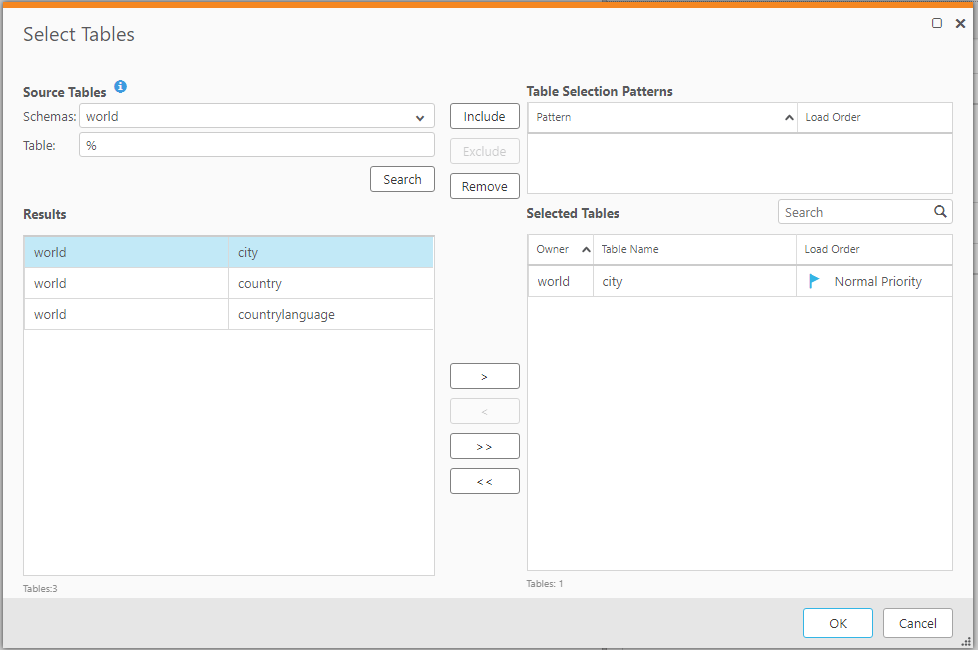
En este caso se utilizará la tabla city del esquema world.
Una vez creada la tarea que replicara los datos hacia el clúster de Kafka, sólo queda iniciar la tarea recién creada presionando Run en la parte superior de la interfaz.
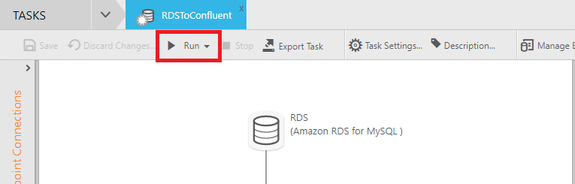
5.6. Producir datos
Una vez presionado Run para iniciar la tarea comienza el Full Load o la carga inicial de datos para observar esto nos debemos dirigir al monitor de Attunity Replicate.
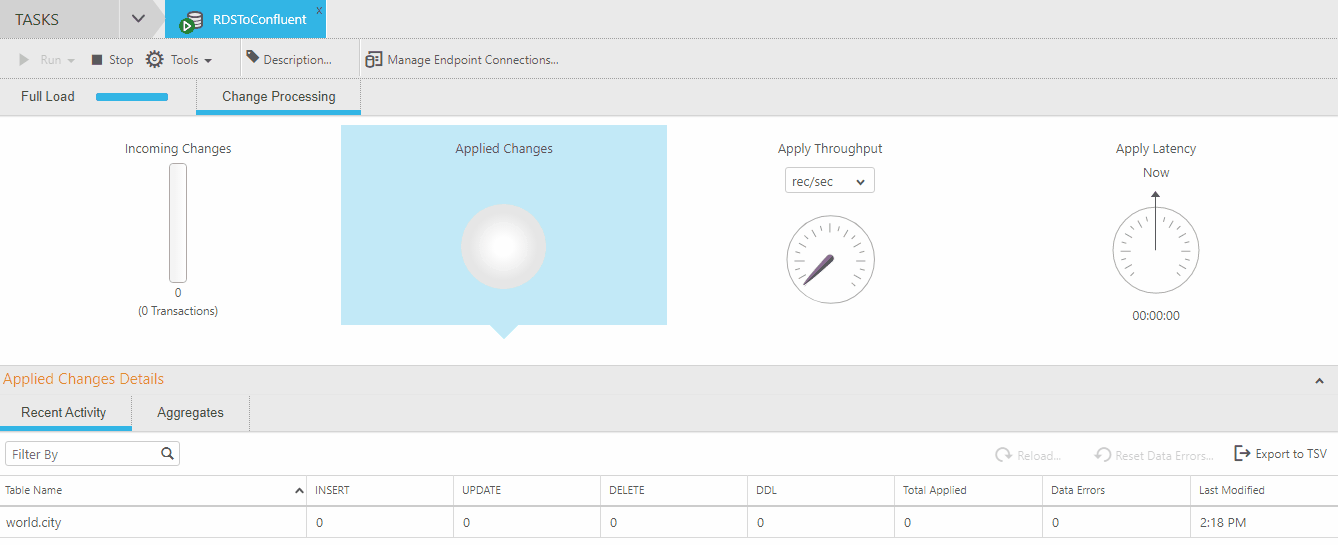
 Luego de realizarse la carga inicial de datos la tarea no se detiene ya que al agregar la opción de Apply Changes queda a la espera de la realización de algún cambio en la base de dato para poder replicar un nuevo mensaje hacia el tópico suscrito.
Luego de realizarse la carga inicial de datos la tarea no se detiene ya que al agregar la opción de Apply Changes queda a la espera de la realización de algún cambio en la base de dato para poder replicar un nuevo mensaje hacia el tópico suscrito.
Para visualizar esto se realiza un nuevo registro en la tabla city en la base de datos contemplando los siguientes datos:
«Name»: «Cibinong»,
«CountryCode»: «IDN»,
«District»: «West Java»,
«Population»: 101300
Una vez realizado esto se visualiza en el monitor de Attunity el cambio realizado en la base de datos
Para observar los mensajes replicados por Attunity Replicate se debe seguir el paso 6 del apartado “Producir y consumir datos localmente” de este mismo documento.
El formato del mensaje obtenido por Amazon MSK es el siguiente:
{
«magic»: «atMSG»,
«type»: «DT»,
«headers»: null,
«messageSchemaId»: null,
«messageSchema»: null,
«message»: {
«data»: {
«ID»: 4097,
«Name»: «Jombang»,
«CountryCode»: «IDN»,
«District»: «East Java»,
«Population»: 92600
},
«beforeData»: null,
«headers»: {
«operation»: «INSERT»,
«changeSequence»: «20200520193227000000000000000000005»,
«timestamp»: «2020-05-20T19:32:27.000»,
«streamPosition»: «mysql-bin-changelog.004646:350:0:416:19954418057435:mysql-bin-changelog.004646:292»,
«transactionId»: «000000000000000000001226000000DB»,
«changeMask»: «1F»,
«columnMask»: «1F»,
«transactionEventCounter»: 1,
«transactionLastEvent»: true
}
}
}
6. Consumidor de datos
Una vez publicados los mensajes en el tópico del clúster de Amazon MSK, se debe crear un consumidor de estos datos, para realizar esto configuraremos un Proxy-Rest en el cliente de Amazon MSK.
Se implementará el Proxy-Rest de Confluent el cual proporciona una interfaz RESTful a un clúster de Kafka, lo que facilita la producción y el consumo de mensajes, ver el estado del clúster y realizar acciones administrativas sin utilizar el protocolo o los clientes nativos de Kafka.
6.1. Configuración Proxy-Rest
Para realizar la configuración del Proxy-Rest se deben seguir los siguientes pasos:
- Paso 1: Ingresar al cliente de Amazon MSK creado con anterioridad desde la consola de Amazon EC2 en https://console.aws.amazon.com/ec2/.
- Paso 2: Descargar y descomprimir confluent utilizando el siguiente comando:
curl -O http://packages.confluent.io/archive/5.5/confluent-5.5.0-2.12.tar.gz
tar xzf confluent-5.5.0-2.12.tar.gz
- Paso 3: Editar el archivo kafka-rest.properties utilizando el siguiente comando:
vim confluent-5.5.0/etc/kafka-rest/kafka-rest.properties
Puede utilizar su editor de texto de su preferencia.
- Paso 4: Reemplazar las líneas que se muestran a continuación por los datos del clúster de Amazon MSK.:zookeeper.connect=
bootstrap.servers=
ZookeeperConnectString obtenido en el paso 2 del apartado “Creación de tópicos” de este mismo documento.
BootstrapBrokerStringobtenido en el paso 1 del apartado “Producir y consumir datos localmente” de este mismo documento.IMPORTANTE: Anteponer PLAINTEXT:// antes de cada broker server
EJEMPLO: PLAINTEXT://b-2.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9092,PLAINTEXT://b-1.kafka-test.m1vlzx.c5.kafka.us-east-1.amazonaws.com:9092
- Paso 5: Navegar hasta la carpeta de confluent:
cd confluent-5.5.0/
- Paso 6: Desplegar el servicio Proxy-Rest de confluent utilizando el siguiente comando:
bin/kafka-rest-start etc/kafka-rest/kafka-rest.properties - Paso 7: Verificar que el servicio está funcionando correctamente ingresando al siguiente endpoint:
http://:8082/topicsSi no hay errores se debe obtener una lista de los tópicos creados en el clúster de Amazon MSK.// 20200521183524
// http://ec2-34-228-240-180.compute-1.amazonaws.com:8082/topics
[
«AWSKafkaTutorialTopic»,
«test»
]
6.2. Api Proxy-Rest
El Proxy-Rest que provee confluent cuenta con diferentes endpoint a los cuales recurrir para administrar Apache Kafka mediante peticiones HTTP. Permite consumir y producir datos, crear y eliminar tópicos, obtener datos de los consumidores, etc.
La documentación de dicha API se encuentra disponible en: https://docs.confluent.io/current/kafka-rest/api.html#crest-api-v2
Se utilizó la versión 2 de esta API.
A continuación se presenta un archivo adjunto que contiene un conjunto de peticiones que permiten probar la API de antes referenciada.
Amazon MSK.postman_collection.json
Archivo compatible con Postman.
Cambiar
el host del clúster de Amazon MSK en cada petición.
6.3. Creación de consumidor
Para la creación del consumidor de los datos, se utilizó NodeJs y la dependencia Kafka-Rest (https://www.npmjs.com/package/kafka-rest).
El código que permite realizar la creación del consumidor es el siguiente:
‘use strict’
var KafkaRest = require(‘kafka-rest’);
var kafka = new KafkaRest({ ‘url’: ‘http://:8082’ });
//Permite crear el consumidor
//NOMBRE_CONSUMIDOR = nombre del consumidor
kafka.consumer(«NOMBRE_CONSUMIDOR»).join({
«format»: «binary»,
«auto.offset.reset»: «smallest»,
«auto.commit.enable»: «false»
}, function (err, consumer_instance) {
//El crear el consumidor retorna una instancia que es la que permite suscribirse al tópico
//TOPICO = nombre del tópico var stream = consumer_instance.subscribe(‘TOPICO’)
//Establece conexión con el tópico y espera la llegada de nuevos mensajes
stream.on(‘data’, function (msgs) {
for (var i = 0; i < msgs.length; i++) {
//Json que contiene metadata del tópico
var metadata = {
«topic»: stream.topic,
«key»: msgs[i].key,
«partition»: msgs[i].partition,
«offset»: msgs[i].offset
}
//Json que contiene el mensaje
//El mensaje viene cifrado en base64
var data = JSON.parse(msgs[i].value.toString(‘utf8’))
console.log({ metadata, data });
}
});
//Actúa cuando existe una interrupción en la conexión con el clúster
stream.on(‘error’, function (err) {
console.log(«Something broke: » + err);
});
});
6.4. Consumo de datos
El código anteriormente expuesto imprime en la consola los mensajes del tópico una vez que son producidos por Attunity Replicate.

El formato del mensaje obtenido es el siguiente:
{
metadata: {
topic: ‘test’,
key: null,
partition: 0,
offset: 16
},
data: {
magic: ‘atMSG’,
type: ‘DT’,
headers: null,
messageSchemaId: null,
messageSchema: null,
message: {
data: {
ID: 1017,
Name: ‘Jombang’,
CountryCode: ‘IDN’,
District: ‘East Java’,
Population: 92600
},
beforeData: null,
headers: {
operation: ‘DELETE’,
changeSequence: ‘20200520194057000000000000000000029’,
timestamp: ‘2020-05-20T19: 40: 57.000′,
streamPosition:’mysql-bin-changelog.004648: 729: 0: 795: 19963007992027:mysql-bin-changelog.004648: 671’,
transactionId: ‘000000000000000000001228000000DB’,
changeMask: ’01’,
columnMask: ‘1F’,
transactionEventCounter: 4,
transactionLastEvent: true
}
}
}
}
7. Conectores
Apache Kafka no sólo permite producir o consumir datos, sino que también permite añadirle conectores que ayudan a sincronizar los mensajes que llegan a un tópico y enviarlos a sistemas externos como bases de datos, almacenes de valores clave, índices de búsqueda y sistemas de archivos. Para realizar esta tarea se utilizará el servicio kafka-connect provisto por Confluent en el cliente de Amazon MSK
Para efectos prácticos se creará un conector que envié los mensajes en formato JSON a un bucket de s3.
7.1. Descargar Plugins
Para realizar esto se deben seguir los siguientes pasos:
- Paso 1: Ingresar al cliente de Amazon MSK creado con anterioridad desde la consola de Amazon EC2 en https://console.aws.amazon.com/ec2/.
- Paso 2: Descargar y descomprimir confluent utilizando el siguiente comando:curl -O http://packages.confluent.io/archive/5.5/confluent-5.5.0-2.12.tar.gz
tar xzf confluent-5.5.0-2.12.tar.gz
Si ya realizó los pasos para configurar el proxy-rest saltarse el paso 2
- Paso 3: descargar y descomprimir el plugin de Amazon S3 en la carpeta principal:wget https://api.hub.confluent.io/api/plugins/confluentinc/kafka-connect-s3/versions/5.5.0/archive
unzip archive
- Paso 4: Crear carpeta para plugins en la carpeta principal:
mkdir plugins
- Paso 5: Crear carpeta dedicada al conector de s3 en la carpeta plugin:
mkdir plugins/kafka-connect-s3
- Paso 6: copiar contenido del plugin descargado en el paso 2 en la carpeta creada en el paso 5:
cp confluentinc-kafka-connect-s3-5.5.0/lib/* plugins/kafka-connect-s3/
7.2. Configuración Kafka-Connect
Para realizar esto se deben seguir los siguientes pasos:
- Paso 1: Editar el archivo connect-standalone.properties utilizando el siguiente comando:
vim confluent-5.5.0/etc/kafka/connect-standalone.properties
- Paso 2: Reemplazar las líneas que se muestran a continuación por los datos solicitados.bootstrap.servers=
plugin.path= BootstrapBrokerString obtenido en el paso 1 del apartado “Producir y consumir datos localmente” de este mismo documento.
PATH_CARPETA_PLUGIN Ruta de la carpeta plugin creada en el paso 4 del apartado anterior.
7.3. Configuración Conector
Para realizar esto se deben seguir los siguientes pasos:
- Paso 1: Editar el archivo quickstart-s3.properties utilizando el siguiente comando:
vim confluent-5.5.0/etc/kafka-connect-s3/quickstart-s3.properties
Dentro del archivo realizar la siguiente configuración:
name=s3-sink
connector.class=io.confluent.connect.s3.S3SinkConnector
tasks.max=1
topics=
s3.region=
s3.bucket.name=
s3.part.size=5242880
flush.size=100000
key.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter: org.apache.kafka.connect.json.JsonConverter
value.conver
ter.schemas.enable: false
storage.class=io.confluent.connect.s3.storage.S3Storage
#format.class=io.confluent.connect.s3.format.avro.AvroFormat
format.class=io.confluent.connect.s3.format.json.JsonFormat
#partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
partitioner.class=io.confluent.connect.storage.partitioner.TimeBasedPartitioner
schema.compatibility=NONE
locale: es_CL
timezone: UTC
path.format: YYYY-MM-dd/HH
partition.duration.ms: 3600000
rotate.interval.ms: 60000
timestamp.extractor: Record
Reemplazar los datos que están entre <>
7.4. Despliegue conexión
Una vez descargado el plugin y configurados los archivos tanto de kafka-connect como del propio conector se procede a desplegar la conexión y ver cómo se sincronizan los mensajes contenidos en un tópico dentro del bucket de S3.
Para desplegar la conexión utilizar el siguiente comando dentro de la carpeta de Confluent:
bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka-connect-s3/quickstart-s3.properties
si no hay problemas se replican los datos del tópico dentro del bucket:
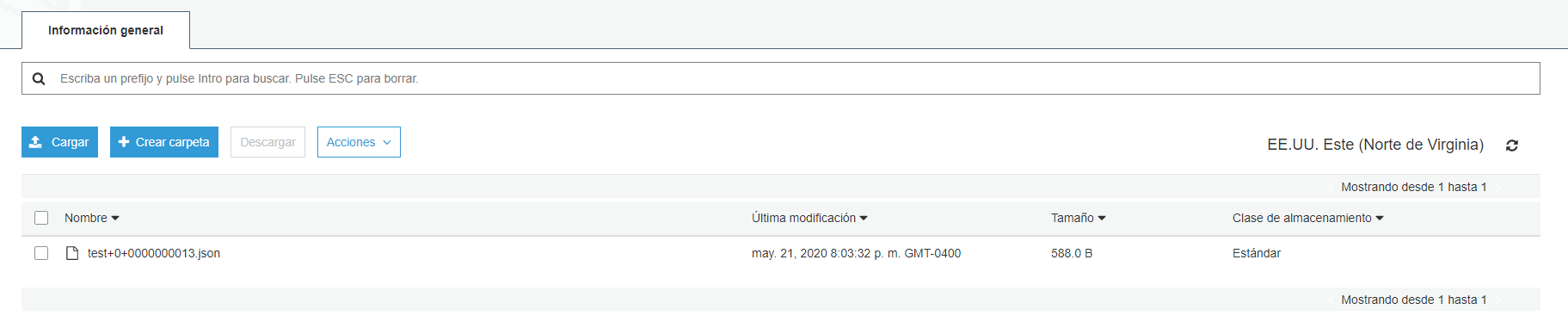
 8. Fail Recovery
8. Fail Recovery
 8. Fail Recovery
8. Fail RecoverySi bien se espera que el sistema no presente fallas al momento de su despliegue hay que tener en consideración como mitigar o solucionar en caso de que ocurran es por esto que se detallarán como se manejan los errores en cada una de las partes.
8.1. Productor
Como se utilizó como productor de datos la herramienta Attunity Replicate esta permite en casos de errores en la conexión de alguno de los conectores de la tarea obtener un log detallado de todos los errores presentes en la operación.
 8.2. Clúster Amazon MSK
8.2. Clúster Amazon MSK
Como principal barrera que tiene Amazon MSK para hacer frente a una posible caída de los servicios es que permite crear y replicar los brokers en distintas zonas de disponibilidad lo que no solo permite obtener una alta disponibilidad de los servicios sino que ayuda a que si ocurre un fallo de uno de los brokers existe otro en una zona de disponibilidad distinta que puede tomar su lugar.
Sin embargo cuando ocurre una falla masiva la única medida que existe en caso de que falle el clúster de Amazon MSK es creando uno nuevo. Por lo que se deben tomar medidas para mitigar o disminuir las consecuencias en caso de requerir realizar esta acción.
Antes de la catástrofe se recomienda utilizar kafka-connect para hacer un backup del stream de mensajes enviándolos a un bucket de s3.
Revisar el apartado Conectores de este mismo documento.
Con el objetivo de que cuando suceda la catástrofe y se requiera crear un clúster nuevo se utilice ese backup de datos.
8.2.1. Procedimiento de recuperación
- Crear el nuevo clúster
- Aislar el clúster antiguo desactivando servicios del clúster, kafka-connect, kafka-rest, etc. (esto para evitar que usuarios traten de conectarse al clúster.)
- Cargar el backup del bucket de s3 en el nuevo cluster (utilizar kafka-connect, conector s3 source).
- Habilitar kafka-connect para el nuevo clúster MSK.
- Cambie informando a todos los servicios sobre el nuevo punto broker server de Kafka
- Habilitar los servicios para que los usuarios pueden usar la aplicación nuevamente.
8.2.2. Métricas
Amazon MSK tiene métricas para medir ciertos aspectos del clúster. Estas metricas estan disponibles en https://docs.aws.amazon.com/es_es/msk/latest/developerguide/monitoring.html.
la única métrica que permite medir el estado de uno de sus elementos es:
ZooKeeperSessionState.
La cual se mide en los siguientes valores.
| NOT_CONNECTED | ‘0.0’ |
| ASSOCIATING | ‘0.1’ |
| CONNECTING | ‘0.5’ |
| CONNECTEDREADONLY | ‘0.8’ |
| CONNECTED | ‘1.0’ |
| CLOSED | ‘5.0’ |
| AUTH_FAILED | ‘10.0’ |
Esta métrica mide el estado de la sesión de ZooKeeper del cluster.
El Zookeeper se utiliza para almacenar el estado de los brokers.
8.3. Consumidor
En caso de que el consumidor presente algún tipo de fallas debe ser capaz de retomar desde el último mensaje consumido.
Para lograr esto se debe configurar el consumidor utilizando las siguientes opciones:
«auto.offset.reset»: «smallest»,
«auto.commit.enable»: «false»
Por defecto en la instancia del consumidor se guarda el offset del último mensaje consumido, por lo que este sabrá dónde retomar la tarea una vez de que ocurra algún tipo de falla en el consumidor.
También se debe configurar cuál será el offset inicial del consumidor. Use auto.offset.reset para definir el comportamiento del consumidor cuando no hay una posición comprometida (que sería el caso cuando el grupo se inicializa por primera vez) o cuando un offset está fuera de rango. Puede elegir restablecer la posición al offset más antiguo smallest o al offset más reciente largest (el valor predeterminado).
Al inicializar auto.commit.enable en false nos aseguramos que solo se realice la transición al siguiente offset cuando el mensaje anterior es recibido de manera satisfactoria, si se inicializa en true realizará la transición o desplazamiento después de un tiempo determinado.



