

AWS Lake Formation
Construir un Data Lake es una tarea que requiere mucho cuidado. Si bien su nivel de complejidad depende de diversos factores, entre ellos:
- diversidad en tipo y orígenes de los datos
- almacenamiento requerido
- exigentes niveles de seguridad
Sin importar las múltiples combinaciones que puedan darse entre estos (y muchos más factores), siempre habrá un elemento común en los posibles escenarios de implementación de un Data Lake: conocimiento global y general del ciclo de vida del dato.
Por definición podríamos considerar que un Data Lake es un enfoque arquitectónico que permite almacenar cantidades masivas de datos en una ubicación central, de manera que estén fácilmente disponibles para ser categorizados, procesados, analizados y consumidos por diversos grupos dentro de una organización.
Una construcción típica de un Data Lake se compone de:
- Configuración del almacenamiento
- Movilización de los datos
- Limpieza, preparación y catálogo de datos
- Configuración y refuerzo de políticas de seguridad y cumplimiento de las mismas
- Asegurar que los datos estén disponibles (para aplicaciones analíticas o de visualización, entre otras)
Como es de suponerse, cada uno de estos puntos representa a su vez un procedimiento más detallado y que debe abordarse con una rigurosidad mayor. De nuevo, las combinaciones entre estos pasos hace que una persona (o empresa) que quiera comenzar a ‘jugar’ con un Data Lake pueda sentirse abrumada.
Curiosamente AWS tiene una enorme gama de servicios de AWS para trabajar con datos que, en ocasiones, puede ‘forzar’ a que una persona simplemente se dé por vencida en su meta de trabajar con un Data Lake.
Antes de revisar la propuesta de AWS Lake Formation, podríamos considerar algunos de los pasos requeridos para construir un Data Lake en AWS:
- Identificar las fuentes de datos (como RDBMS, archivos, streams, transacciones)
- Crear los buckets en S3 necesarios para almacenar estos datos, con sus correspondientes políticas
- Crear los ETLs que van a realizar las transformaciones de esos datos desde sus orígenes para llevarlos a los buckets S3. Esto supone la correspondiente administración de políticas de auditoría y permisos de los ETLs, y crear una estrategia de limpieza de datos.
- Permitir que los servicios de analytics accedan a estos datos en S3.
En el proceso anterior cada punto implica un factor humano de riesgo por posibles errores que puedan cometerse. Las 2 ‘rutas alternativas’ serían ejecutar manualmente con total minucia el proceso, generando un checklist e identificando a su vez cada una de las nuevas alternativas en cada punto; o bien, apoyarse en un servicio administrado que se encargue de la mayor cantidad posible de tareas para la creación del Data Lake. Y es en este punto donde entra AWS Lake Formation:
 AWS Lake Formation es una opción atractiva para aquellas personas que no posean el conocimiento técnico o el tiempo necesarios para enfrentar un proyecto que involucre un Data Lake.
AWS Lake Formation es una opción atractiva para aquellas personas que no posean el conocimiento técnico o el tiempo necesarios para enfrentar un proyecto que involucre un Data Lake.
Como se puede observar en la imagen anterior, AWS Lake Formation comprende las 4 etapas básicas de un Data Lake, permitiendo en cada una de ellas una interacción humana al nivel que sea deseado por el usuario. Dicho de otra forma, quien quiera hacer un ‘doble clic’ en alguna de estas 4 fases podrá hacerlo.
En AWS Lake Formation, S3 se encarga de la capa de almacenamiento. El usuario tendrá acceso a sus datos sin que exista algún tipo de ‘bloqueo’ por parte del servicio. Se pueden hacer cargas de una sola ejecución o incrementales. Se trata de indicar el origen y destino de los datos, y especificar con qué frecuencia se realizará la carga. Esta configuración se realiza por medio de ‘planos’ (blueprints).
Lake Formation se apoya en ML Transforms para crear transformaciones con Machine Learning, las cuales se utilizan en un job ETL (por ejemplo). Una de estas transformaciones es FindMatches la cual ayuda a administrar los duplicados de datos.
Como herramienta para catalogar los datos, AWS Lake Formation utiliza crawlers de AWS Glue para obtener los metadatos y crear un catálogo con ellos. Posteriormente, estos se pueden utilizar para etiquetar la información (por ejemplo, marcar información como sensible).
El usuario administrador podrá crear los accesos que considere convenientes, y AWS Lake Formation se encargará de bloquear o permitir el acceso a los datos (o los servicios que los utilicen) a otros usuarios:
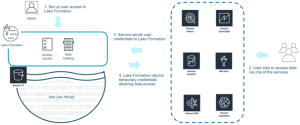
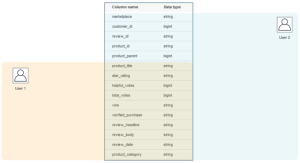
Estos permisos pueden ser a nivel de tabla y de columna:
AWS Lake Formation permite auditar desde un único punto, sin necesidad de recorrer múltiples servicios. Este monitoreo puede hacerse en tiempo real.
Un aspecto fuerte en este nuevo servicio es su costo: sólo se paga por los servicios subyacentes, es decir, AWS Lake Formation es gratis. Sólo se cobrará por los servicios que se invoquen a partir de él.
Después de haber revisado de manera inicial el servicio de AWS Lake Formation, podríamos decir que estamos ante un servicio que permitirá a los usuarios (tanto principiantes como expertos) comenzar de manera casi inmediata con un Data Lake básico. No sólo esto, sino que permitirá ‘abstraer’ los detalles técnicos complejos de implementar un Data Lake básico, y enfocar los esfuerzos en tareas más específicas del negocio. Sin embargo vale la pena resaltar la palabra básico, ya que en la medida en que la solución Big Data tenga un nivel de complejidad mayor, podría ser necesario revisar los requerimientos por completo y en este punto el alcance esté por fuera de AWS Lake Formation.
Fuentes:
- AWS Lake Formation for Data Lakes
- Introduction to AWS Lake Formation. Prajakta Damle, Principal Product Manager, AWS Lake Formation & AWS Glue
- https://pages.awscloud.com/lake-formation-preview.html



